7.1 智能体(Agent)简述
基于大语言模型的上层应用,已经从基于提示词、无状态、无计划和无记忆的阶段,进入到了更加复杂的阶段,这个阶段需要结合工程实践来赋能大语言模型,虽然大模型在推理阶段只是面向上下文,但是我们可以通过外挂的方式,通过一些传统的工程实现来使得整个 AI 应用和服务变成有状态、有计划和有记忆的存在。到这里我们就会触及 AI Agent 这个 LLM 上层应用形态,也是目前以及未来都会很流行的东西。 那么什么是 AI Agent 呢?很多人有不同的认知,我认为 AI Agent 就是给大模型工具和环境,这样大模型可以在思考后决定采用什么动作,这其中就有通过工具使用来感知环境,这样可以得到外部的信息,比如命令行执行的结果,请求 API 的结果,网页搜索的结果,甚至是物理世界的视觉反馈或传感器的结果。基于这些信息,AI Agent 可以结合自身在训练阶段得到的通识能力去做决策、执行和判断。这种也是目前以 ReAct 为基础的一种 AI Agent 的通用范式。 另外,Agent 相比于 RAG 和提示词技术这些来说是更加复杂的系统,需要在稳定且连续的情况之下,让大模型通过计划、执行和观察等手段实现多轮次的循环,直到最终解决问题。这其中不是简单的写下提示词,对接外部工具和大模型就行,更多的还是在于从系统层面进行调度的能力,推理和执行链路,以及状态和记忆的管理,包括一些边界情况的管控和收敛。因此我们会认为 AI Agent 的能力体现可以用以下的等式来表示: AI Agent=80% 的工程能力 +20% 的 AI 因为底座是基于大语言模型(LLMs),也有一些提示词相关的技术,其他的更多还是涉及传统行业的工程技术,不管是缓存,还是上下文存储、置换等技术,因此到 Agent 这里,可以认为是需要有工程化能力的同时还具备 AI 思维。 在脱离研究层面往应用层面走的过程中,我们会越来越容易感受到这个现象,我们需要从最基础的提示词设计开始,到记忆、知识库、工具的管理,再到整个 Workflow 的编排,甚至进一步到多 Agent 的编排和协作,除了这些以外,我们还需要涉及到一些可观测的铺设,数据采集回补调优,还需要弹性部署(可以是云原生那一套)和监控(也是云原生那一套),甚至还需要沙盒环境,长短周期任务执行引擎等。 可能看到这里有些人会觉得没有这么复杂,其实这恰巧反映了现在的情况。现在我们其实可以花几天就可以做出一个 AI Agent,但是这是一个 Toy Agent,大白话就是一个玩具,0-1 的一个 MVP,我们随便用一个 AI Agent 的框架就可以轻松 Build 出来,网上有大把的教程,但是现实和理想之间的 Gap 是非常大的,一旦我们进入到追求有业务价值、有商业价值的 AI Agent 层面,不是一个人一个 AI 几天就能做出来的,通常需要花费团队很多时间精力和资源去优化,我相信这个也是 2025 年剩下的日子里和 2026 年最大的研究课题和应用方向了。 下面我们来看一张 Letta 去年整理的一张图:
7.2 智能体设计范式
7.2.1 ReAct
在基础提示技术章节中我们也有提到 ReAct,实际上 ReAct 的思想在 Agent 领域得到了最大的发挥,其思想也在很大程度上影响了后面出现的一些框架。ReAct 也已经在生产环境得到了验证,是一个 Agent Loop 的通解。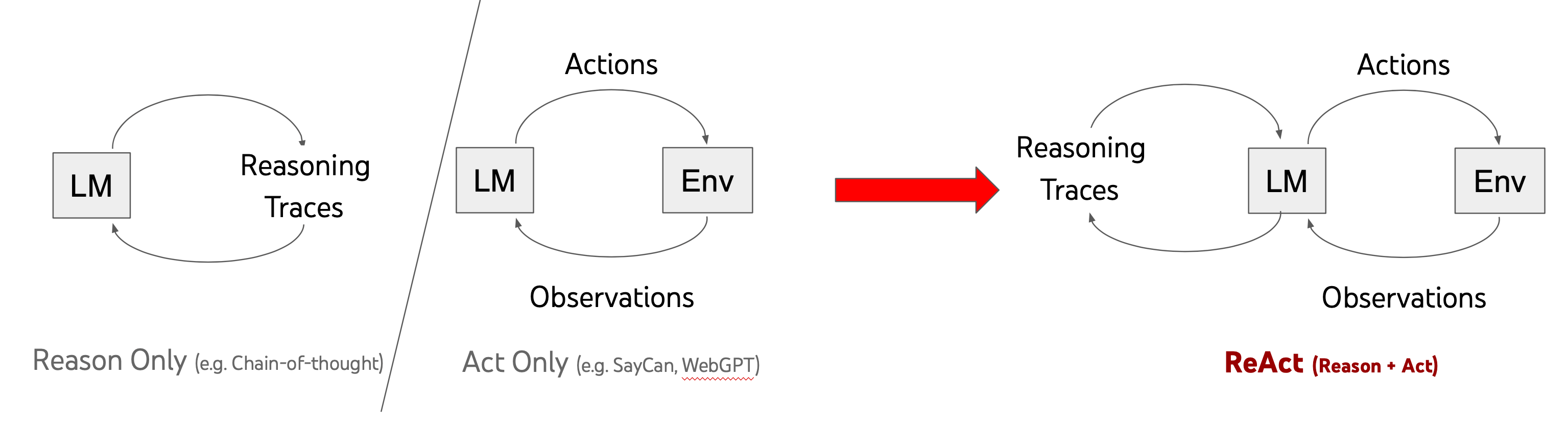

- Loop:其实也就是循环,类比人类解决一个问题,就是不断去尝试,直到解决,这就是一个循环,只不过循环长短不同,人的一生也可以看作是一个大几十年上百年的 Loop。
- Tokens:这算是一个比较 Tech 的说法了,就是 Loop 中,就是不断的去让大模型思考决策,行动,和收集反馈信息继续下次的计划和执行。这个其实也是 ReAct 的核心思想了
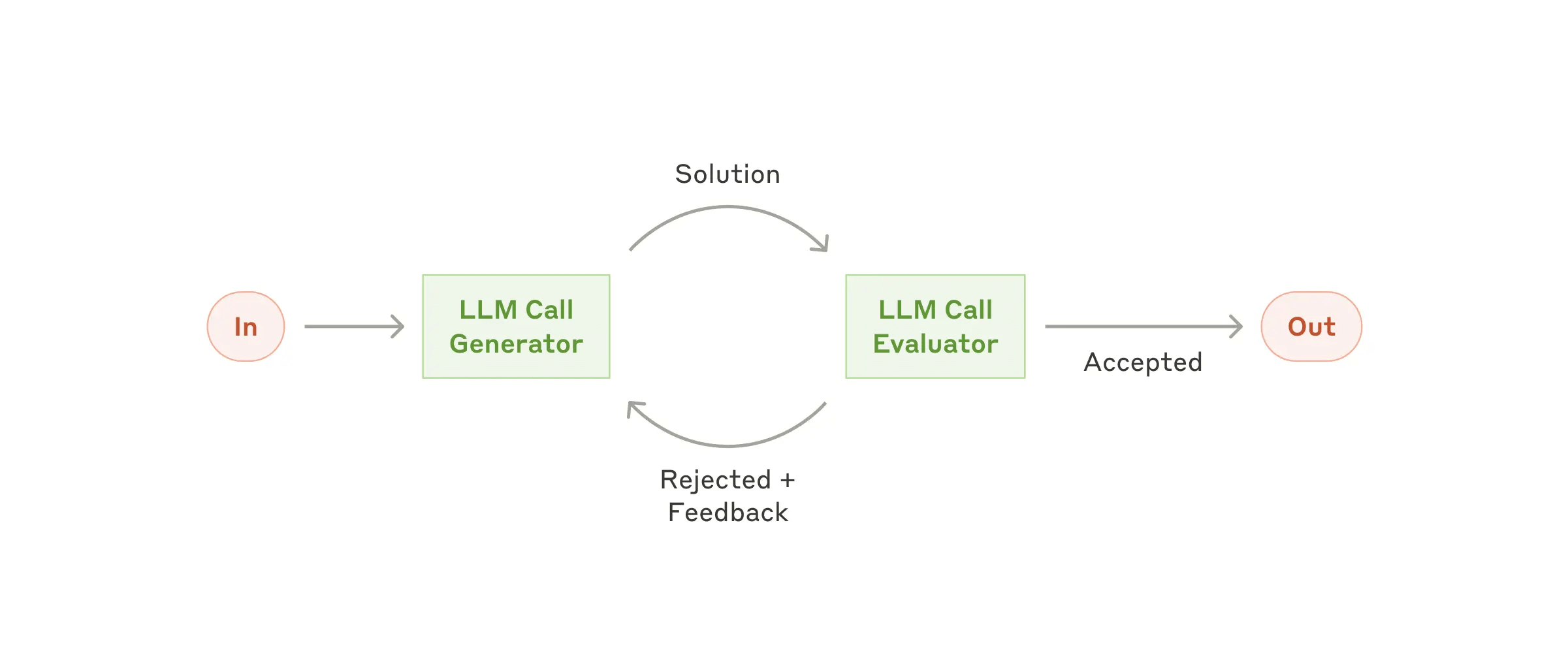
7.2.2 Self-Reflection
Self-Reflection 是 Noah Shinn 等人在 2025 年 5 月提出的(后发布在当年的 NeurIPS)。可以理解是带了复盘系统的 Agent,架构如下: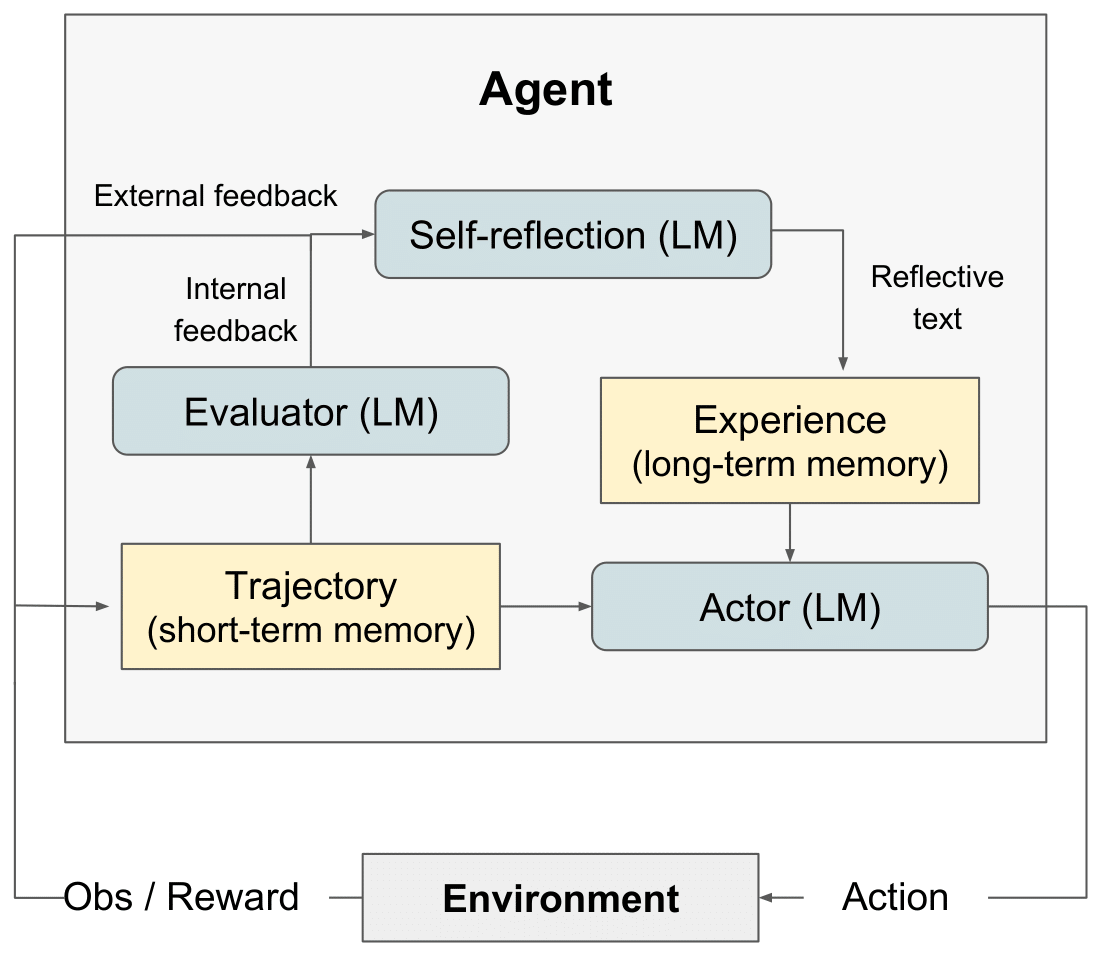
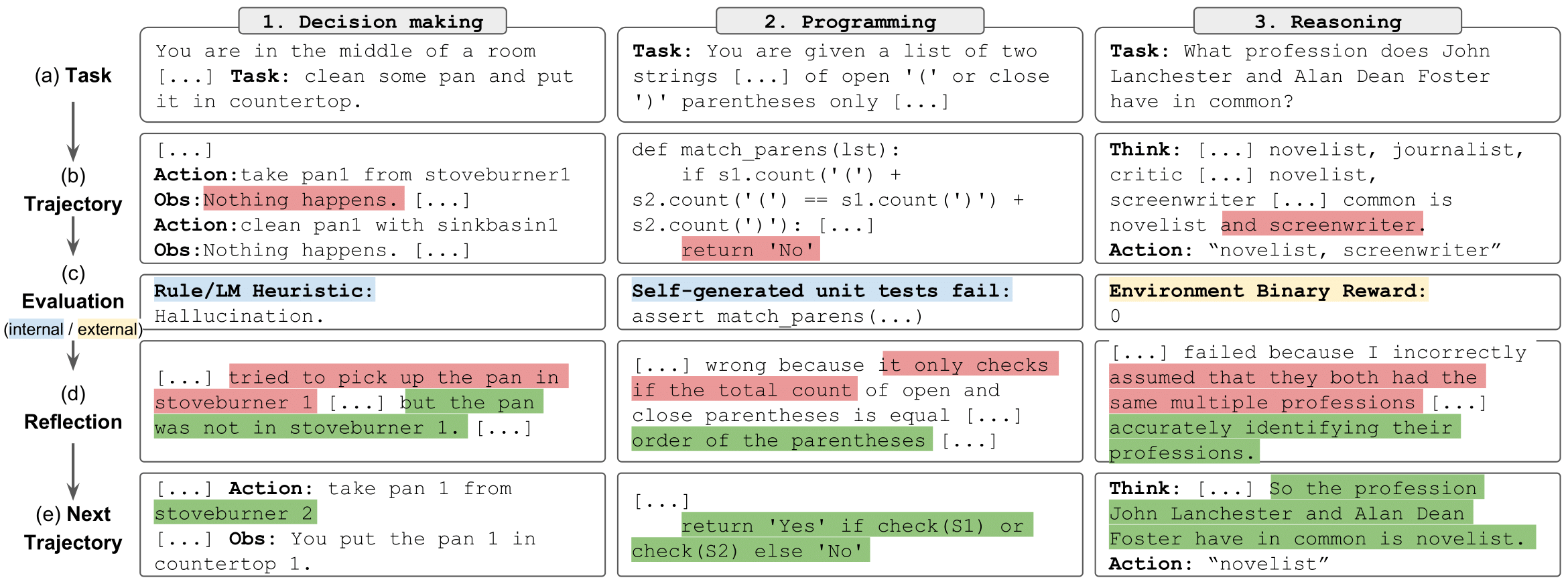
7.2.3 CodeAct
CodeAct 是以 Xingyao Wang 为首的几个人在 2024 年 2 月提出来的,在那之后的 2024 年 3 月 OpenHands(原 OpenDevin)诞生了,Xingyao 也把这个应用到了 OpenHands 中。 CodeAct 的核心思想很简单,就是让大模型输出并执行可执行代码,实现高效、精准的工具调用,以进一步完成复杂任务的手段。说到这里聪明的你应该也想到这个怎么和工具调用或函数调用(Tool/Function Calling)有点类似?实际上 CodeAct 和函数调用都是为了让大模型调用外部工具而设计的机制,只不过有一些差别:- 函数调用通常定义对应的调用格式,比如 JSON,难以实现复杂操作
- CodeAct 可以通过 LLM 生成完整的可执行的 Python 代码,支持较为复杂的操作
7.2.4 Workflow
我觉得工作流 Workflow 也可以列在 Agent 设计范式里,以 Coze、Dify、n8n 等为主的工作流编排是一个很重要的应用分支。我们也可以看到很多人在讨论Agent or Workflow? 这个就需要我们先分辨一下这两者的差别了 引用 n8n 官方 repo 里的这张图:
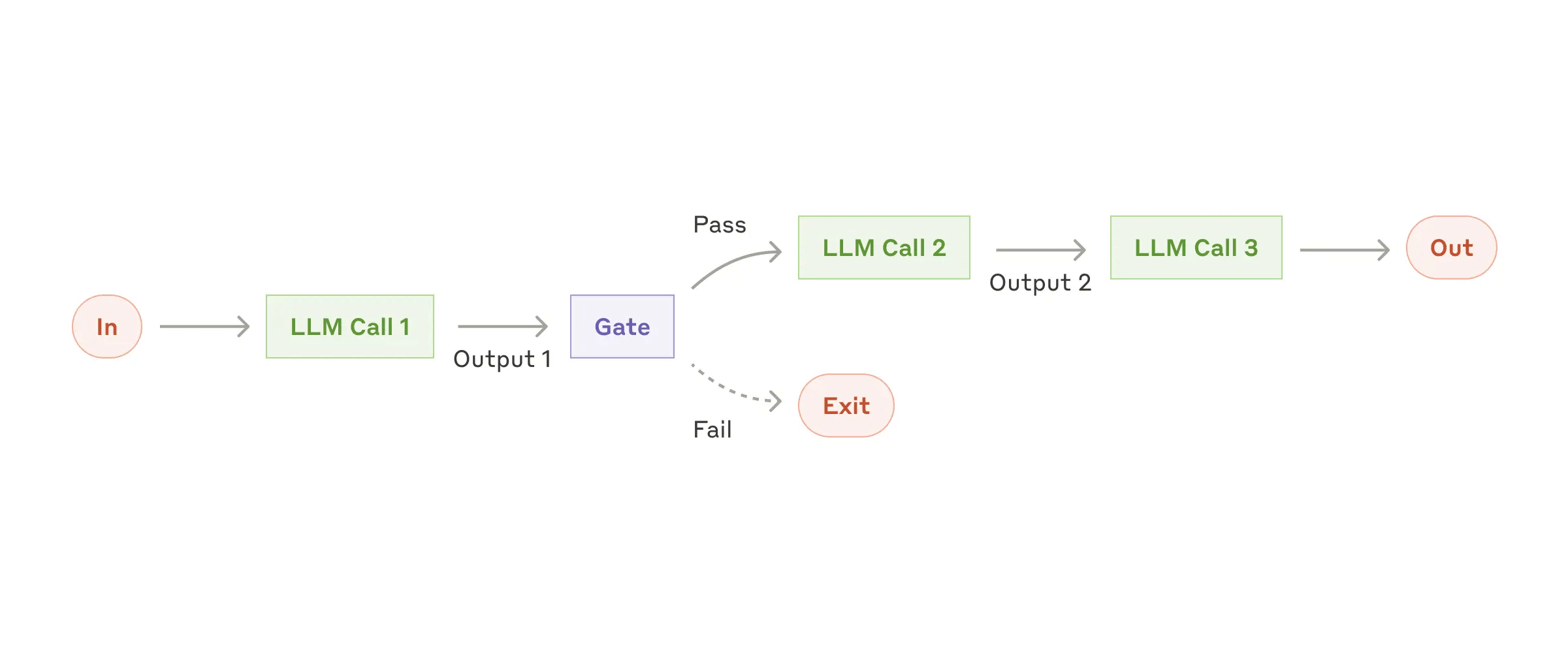
Prompt chaining decomposes a task into a sequence of steps, where each LLM call processes the output of the previous one. You can add programmatic checks (see “gate” in the diagram below) on any intermediate steps to ensure that the process is still on track.Prompt Chaining 就是前一个输出给到下一个输入,串联了多个节点,这多个节点可能同时都请求了大模型,但是可能拥有不同的 Prompt。
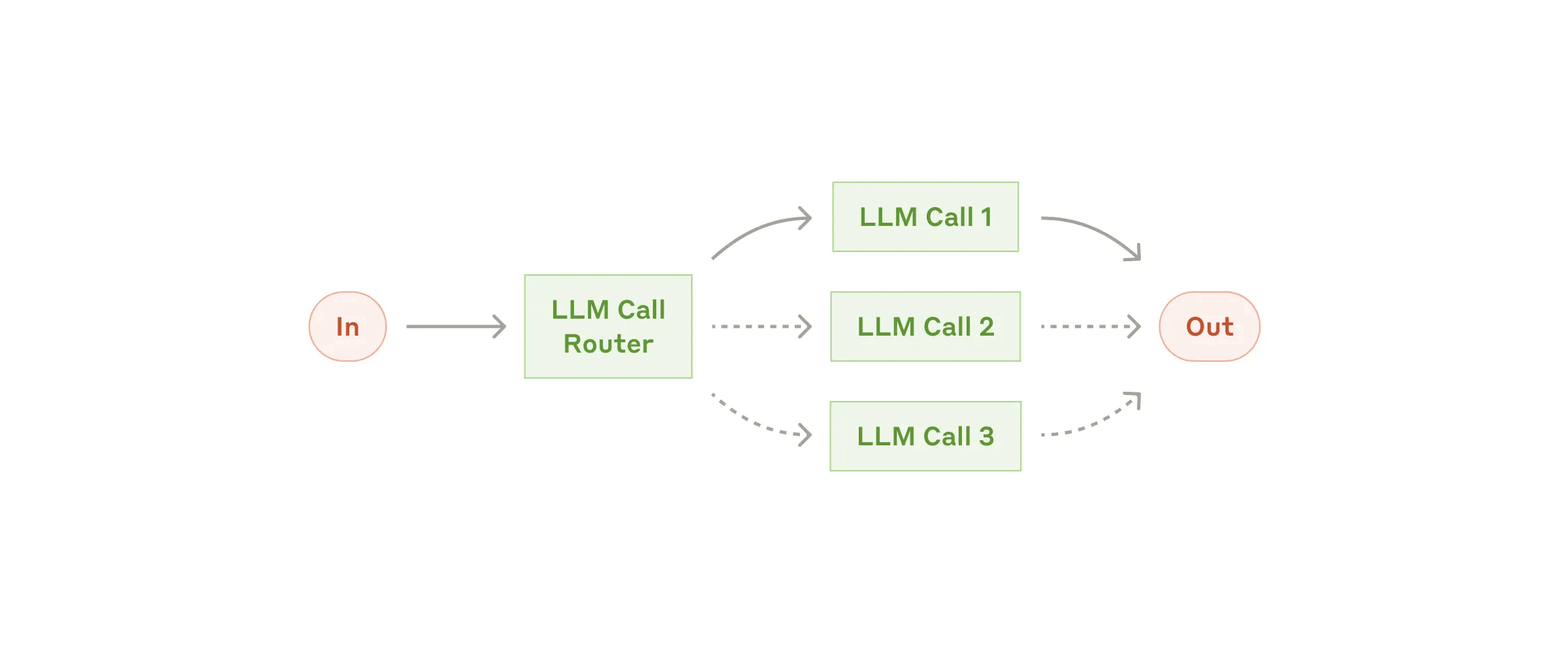
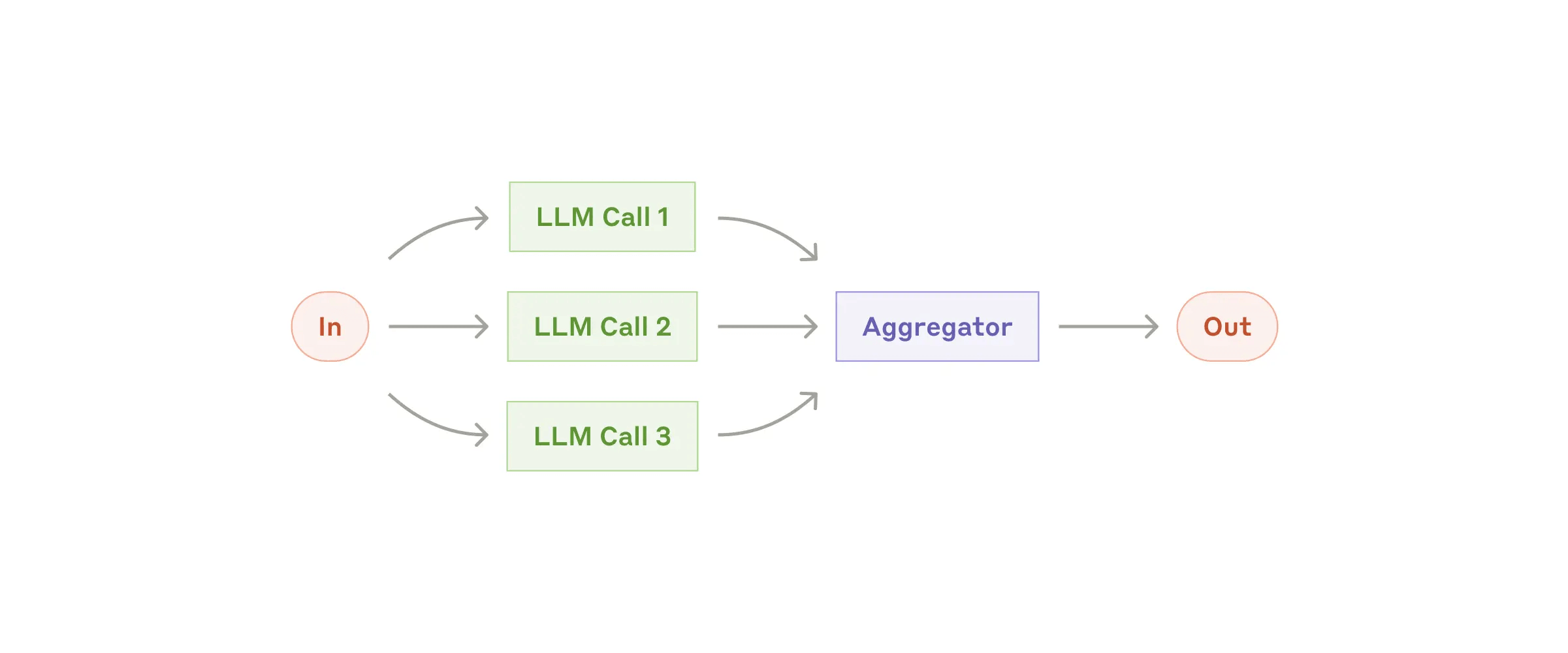
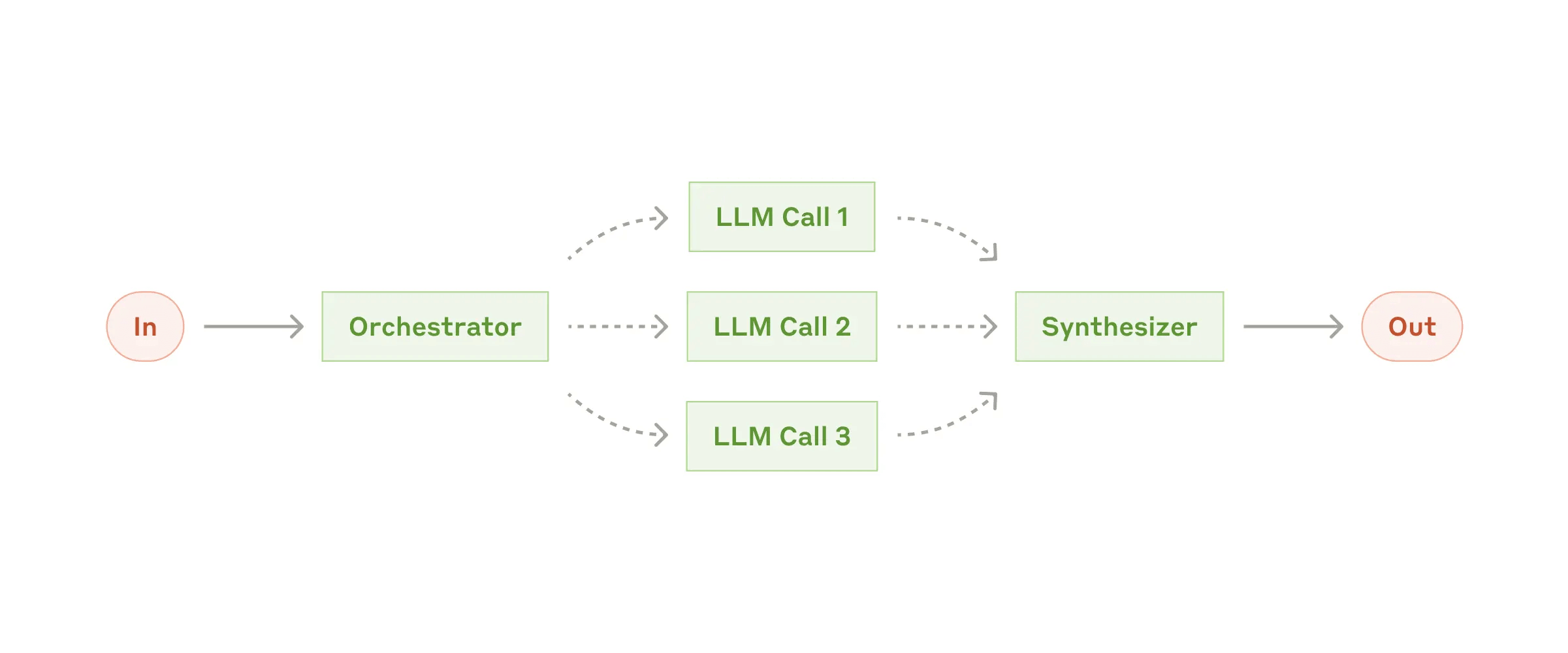
When to use this workflow: This workflow is ideal for situations where the task can be easily and cleanly decomposed into fixed subtasks. The main goal is to trade off latency for higher accuracy, by making each LLM call an easier task.Workflow 适合任务是可以被清除的解构成固定的子任务单元。Workflow 相对于 Agent 有个天然的优势就是高效率,且效果非常稳定,执行基本都能在预期范围内,不可预知或者说未知性很低。缺点自然就是不够灵活了,面对一些开放的或者无法预定义的任务就无法处理了。有一句话特别好:Workflow 和 Agent 的差别在于控制权,Workflow 是程序控制模型,而 Agent 是模型控制程序。 现在大家的一个共识是基于 Routing 去做路由,可以路由到 Workflow,也可以路由到 Agent,这样可以让已知的场景可以稳定高效的执行,未知的场景可以 Agent 兜底自主决策。 简单用一个表格来对比 Workflow 和 Agent:
| 比较维度 | Workflow(工作流) | Agent(智能体) |
|---|---|---|
| 控制方式 | 由程序控制模型:流程固定、按代码路径执行 | 由模型控制程序:模型自行决定步骤与工具调用 |
| 任务结构 | 预定义、可预测的任务链(步骤确定) | 开放式、动态任务(步骤数量和顺序不确定) |
| 灵活性 | 低:只能按既定流程执行 | 高:可根据环境反馈自主调整策略 |
| 可预测性 / 稳定性 | 高,可重复执行,结果一致 | 较低,结果可能随模型推理变化 |
| 实现复杂度 | 较低,逻辑清晰、易测试 | 较高,需要规划、记忆、工具使用等机制 |
| 调试难度 | 易调试,路径明确 | 难调试,推理路径和中间状态复杂 |
| 执行效率 | 快、成本低(少交互) | 慢、成本高(多回合交互) |
| 适用场景 | - 固定流程(如问答、摘要) - 可分解任务(如 Prompt Chaining) | - 无法预定义步骤的任务 - 需要探索、决策、使用工具的场景 |
| 错误恢复机制 | 静态:依靠预设的检查点或验证 | 动态:模型可通过环境反馈或人类输入自我修正 |
| 人类交互 | 通常只在输入/输出阶段交互 | 可多轮交互、在人类反馈下持续调整 |
| 代表模式 | Prompt Chaining、Routing、Parallelization、Orchestrator-Workers、Evaluator-Optimizer | Autonomous Agent(自治代理) |
| 典型案例 | 内容生成流水线、分类路由、代码审查自动化 | 编程智能体(如 SWE-bench)、客服智能体 |
| 主要风险 | 流程死板,难以应对异常输入 | 自治过度、成本高、容易累积错误 |
| 控制策略 | 代码逻辑定义 | 通过 sandbox、终止条件、人工 checkpoint 控制 |
7.2.5 Multi-Agent
当面对复杂任务的时候,通常会将任务拆解成多个子任务来处理,这样有助于追踪完成情况,也有助于 Agent 可以专注于某个子任务的执行。这个也是 Planning+Action 的思路,但是在实际应用中会发现,任务复杂度不断提高的情况下,Agent 的上下文里会充满了各种工具调用的信息,哪怕前一个任务执行完后,执行那个任务的相关信息依然滞留在上下文里,导致上下文不断膨胀,最终可能影响后续任务的执行和最终结果的输出。 基于这样的背景之下,结合我们之前学习的上下文隔离手段,现在行业里普遍的做法是使用多智能体(Multi-Agent)的架构来组织多智能体,这样可以将不同的子任务交给对应的 Agent 来执行,达到上下文隔离和每个 Agent 独立迭代优化的目的。 从理论角度看有不少多智能体的组织方式(甚至类似网络拓扑的感觉),比如 ddd 这张图就展示了 7 种: 但是在实践过程中最流行的是 Supervisor(或 LeadAgent、Orchestrator)+SubAgent 的组织方式(对应图里的 Hierarchical),其实就是主 Agent+ 子 Agent 的方式。
但是在实践过程中最流行的是 Supervisor(或 LeadAgent、Orchestrator)+SubAgent 的组织方式(对应图里的 Hierarchical),其实就是主 Agent+ 子 Agent 的方式。
7.2.6 小结
到这里已经了解了一些流行的范式,其实从更高维度来划分是可以划分为:- Single Agent(单智能体):以 ReAct 为主,Self-Reflection 和 CodeAct 还有其他的变种都可算作这个分类
- Workflow(工作流):以 DAG 去编排节点,LangGraph、Dify、Coze 等在一定程度上都可以看作是工作流的一种
- Multi-Agent(多智能体):不管是 Swarm 还是 Supervisor,本质上都是将上下文隔离拆分进不同的 Agent 实例的一种多 Agent 组织和写作方式
- Hybrid(混合模式):可能混合以上的内容,最常见的就是通过 Workflow 形式来编排 Agent,典型例子就是通过 LangGraph 编排,本质上是工作流,但是内部的节点有可能是 Agent 在执行。还有一种是通过意图判断和路由层来将已知的场景路由到工作流,未知的场景用 Agent 来兜底
| 范式 | 核心本质 | 什么时候用 | 优势 | 代价与风险 | 一句话理解 |
|---|---|---|---|---|---|
| Single Agent单智能体 | 大模型推理+工具(ReAct / Reflection / CodeAct 等都归此类) | 任务模糊、探索阶段、低结构任务 | 灵活、开发快、无需提前建流程 | 稳定性差、难复现、debug困难、成本不确定 | 大模型自己干到底 |
| Workflow工作流 | 固定步骤编排,流程先定、LLM补洞 | 任务链固定、强策略、安全合规、企业级交付 | 可控、可测试、便宜、低延迟、符合工程质量 | 创造力有限,遇未知场景会卡住 | 流程机器人 |
| Multi-Agent多智能体协作 | 角色分工 + 多上下文隔离(平行/监督) | 大型任务、多维审查、专家协作体系 | 模块化、覆盖全面、可扩展 | 系统复杂、易过度设计、成本上升 | 多专家团队 |
| Hybrid混合模式 | Workflow主干+大模型决策节点 意图/路由+预定工作流+Agent兜底 | 工业级智能系统、流程+智能兼具、具备长尾处理 | 稳定+智能、成本良好、可灰度进化 | 架构设计要求高,需要工程纪律 | 能走规则走规则,遇未知才动脑 |
7.3 总结
相信前面的内容让我们对于 Agent 有了一个全局的认知了,接下去基本上是 HandsOn 去尝试,从 Toy、Demo 和 MVP 出发,最终打造出 Production-Ready 的 Agent,在这期间有几个关键点有助于在选型和迭代过程中去辅助决策:- 权衡好延迟、费用和性能,这能进一步决定是采用 workflow、agent 还是混合两者
- 平衡好控制和授权的关系,可以更好地选择合适的 agent 系统设计范式
- 用最简单有效的手段达到既定目标

Implementing this practice is much easier said than done我相信这也是现在为什么上下文工程是一个非共识的实践学科。因为好坏、合适之类的标准都是比较难以量化的。我坚信能不断推动效果提升的主要集中在这么几点上:
- 有夯实的认知:对于现有的可行技术有个全面的认知,可以随意取用
- 能积极跟进前沿技术的发展:不管是个人还是企业,都可以在这块赢得时间差的优势
- 迭代,快速迭代:只有这样才可以不断推陈出新,包括不断试错和探索
- 保持不断重构现有产品和架构的能力和意识:技术发展伴随着不断重建
- 闭环能力:部署只是开始,需要不断收集数据进行调优和改进