5.1 RAG 基础与原理
5.1.1 RAG 基础概念
检索增强生成(RAG,Retrieval-Augmented Generation)是由 Facebook(现 Meta) AI Research 在 2020 年的一篇论文中出的一个技术,提出的原因是大语言模型(LLM)虽然在各种任务上表现优异,但由于知识存储在参数中,无法及时更新且易出现幻觉(Hallucination);因此引入外部可检索的非参数化记忆,并将检索结果与模型结合,从而提升知识密集型任务的准确性与可追溯性。 简单的人话表述就是,大模型需要外部的信息来帮助决策,提前将文档通过一些手段(分块、向量化等)存起来后,查询的时候可以在这些内容中搜索辅助大模型进行最终的回答,整个流程下来就是 RAG 要做的一个事情。 RAG 能流行是因为其解决了这么几个问题:- 解决推理使用的是过时的训练语料库:尤其针对一些对时间较为敏感的数据,以及一些个人/企业知识库需要最新的
- 缓解幻觉(Hallucination):RAG 可以极强的缓解幻觉,这个核心还是因为模型基于上下文进行推理的过程可以产生更加可靠的结果
- 通用模型专业化:尤其针对垂直领域时,通用模型权重过于分散,在搭配该领域的知识库后,可以有效提升专业化,提高结果的可靠性
5.1.2 架构与工作流程
接下去我们来看看 RAG 相关的架构和流程,这边我画了一张 RAG 架构图: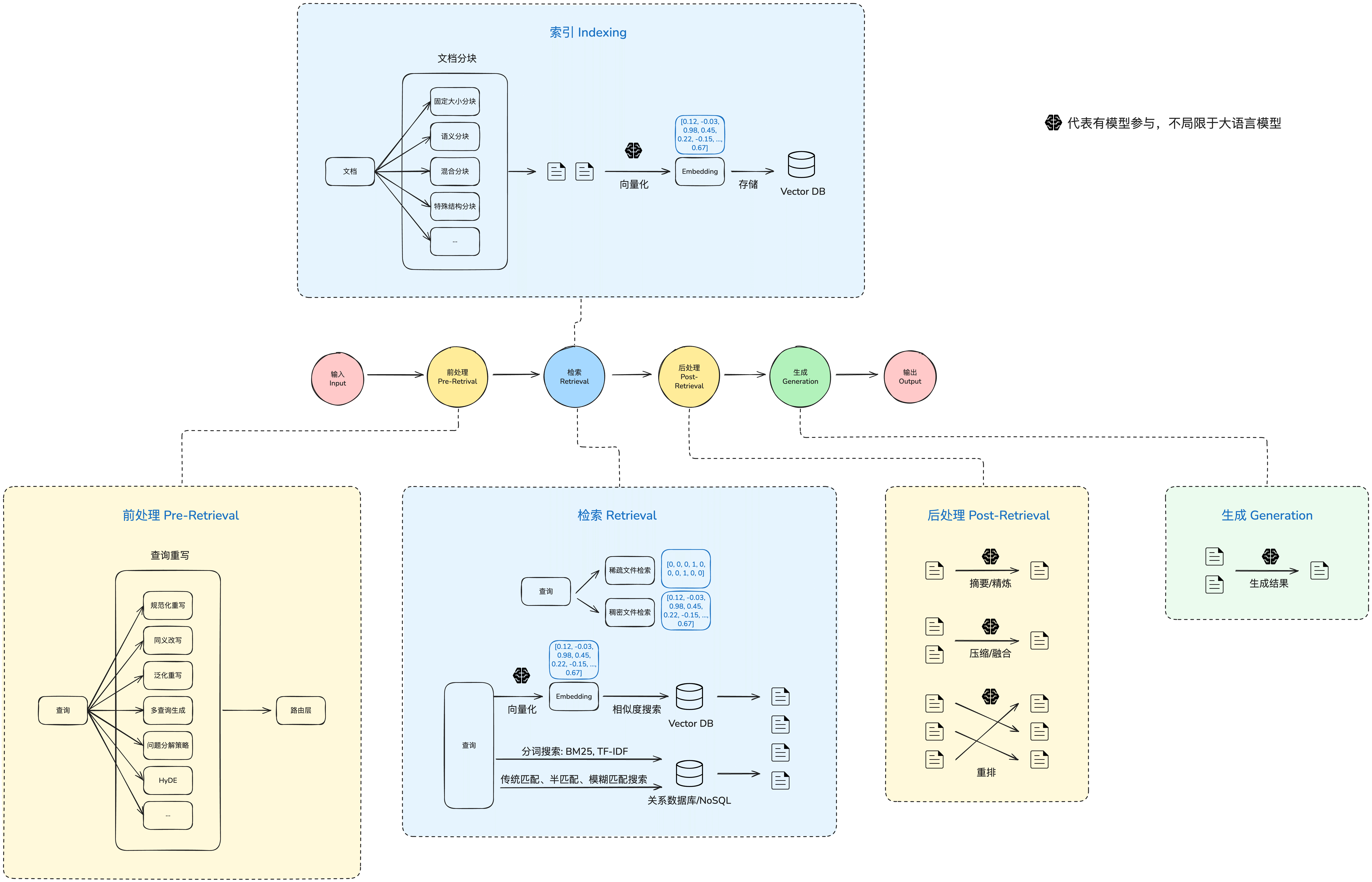
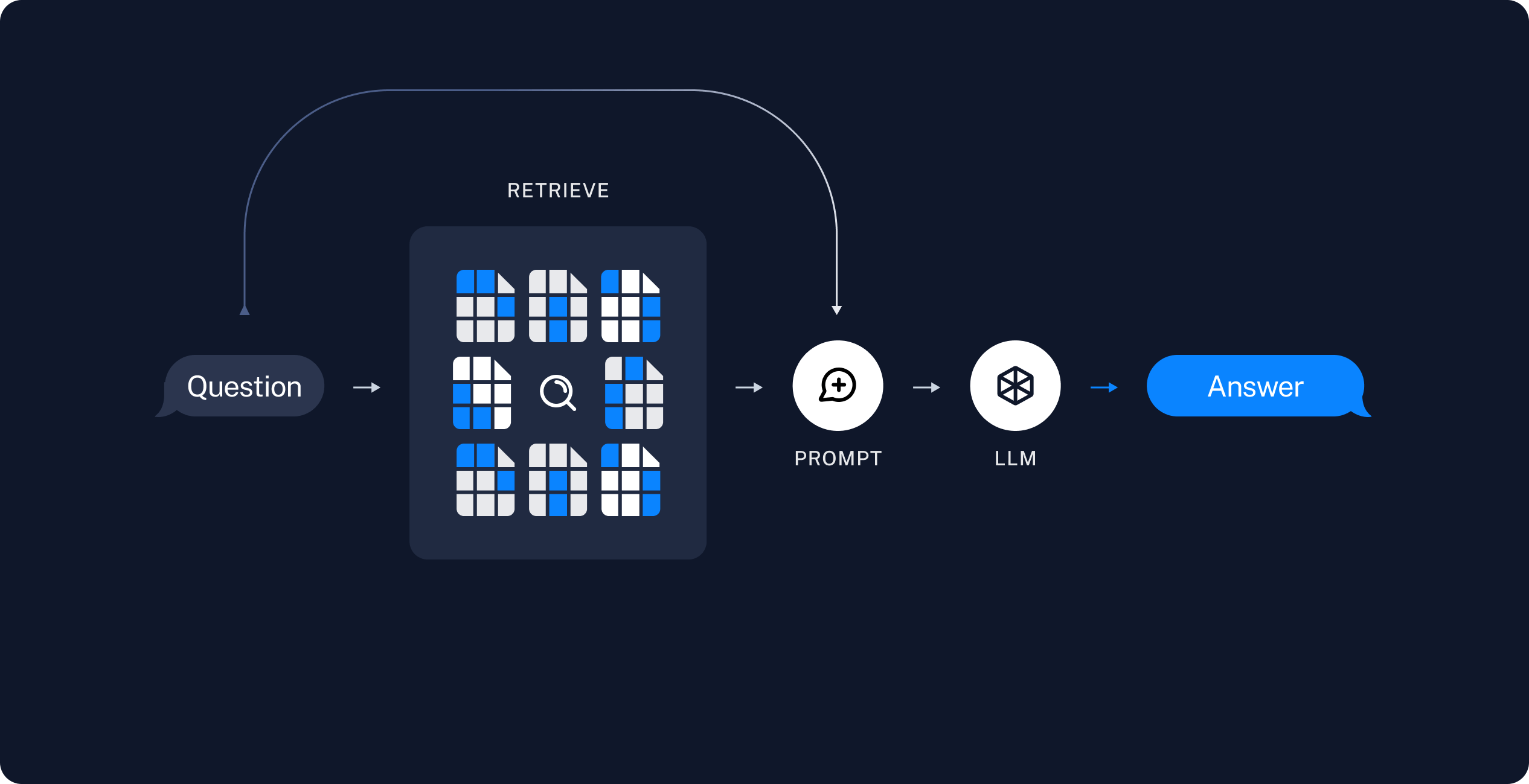
- 查询(Query):输入,通常为用户的查询或者问题等
- 检索(Retriever):从相关知识库中获得与用户问题相关性最高的文档(Top K)
- 生成(Generation):根据 Query 和检索得到的文档,生成高质量的回答
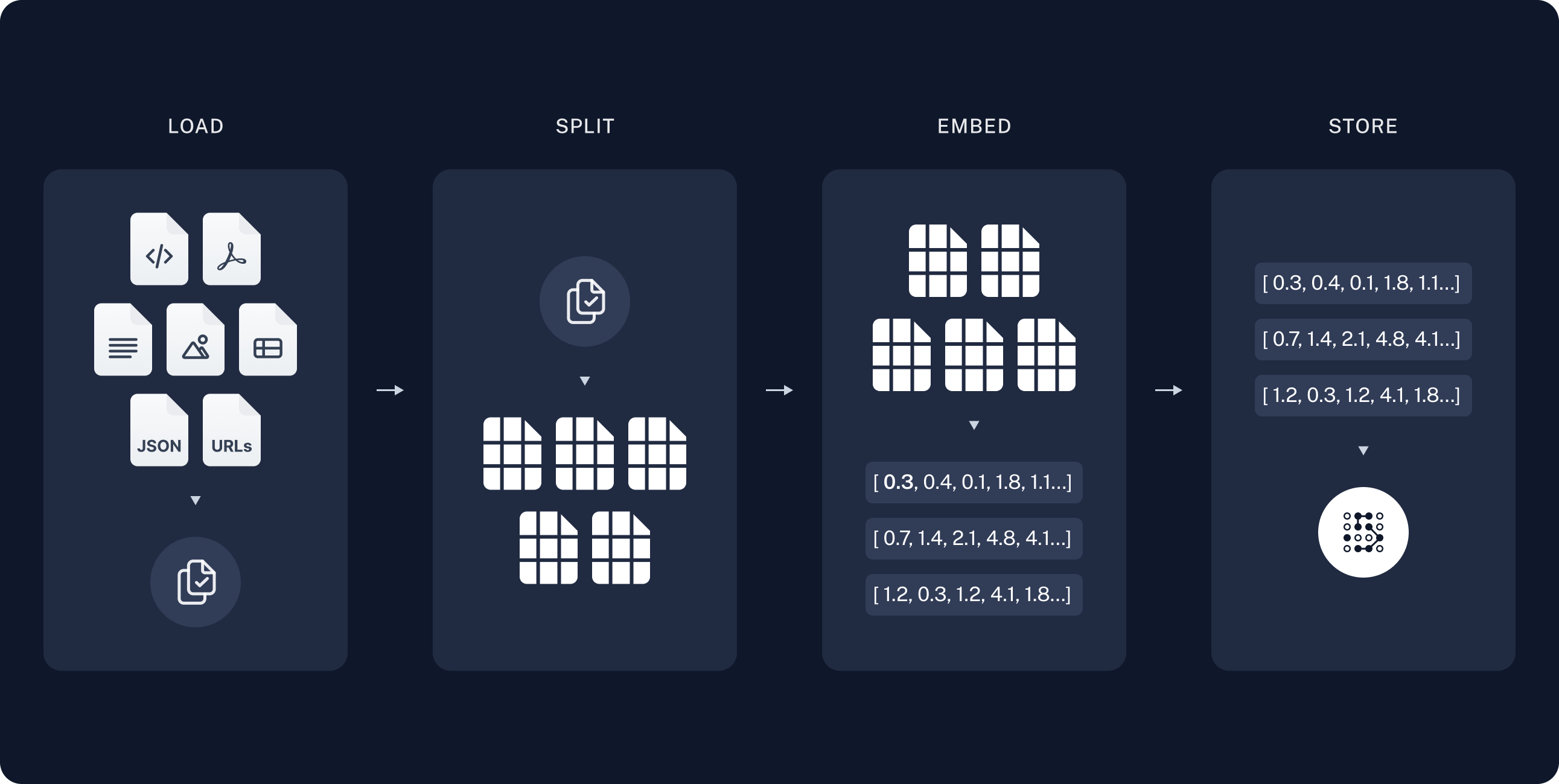
- 数据通过合理的分块(chunking),每块分别做向量化(embedding)后存到向量数据库
- 查询进来后,将查询问题也通过同样的方式向量化后,去到向量数据库内做相似性搜索
- 将搜索得到的 top-k 文档块的原始数据拼接后放在上下文中一起发送给大语言模型
- 大语言模型基于响应的数据做最后的结果生成
5.1.3 检索方式
在自然语言处理中有文本检索技术,分为:- 稀疏文本检索(Sparse Retrieval)
- 稠密文本检索(Dense Retrieval)
稀疏文本检索(Sparse Retrieval)
原理是基于词频(Term Frequency)等显式词项统计信息,使用稀疏向量(Sparse Vector)表示文本,使用向量相似度进行匹配,返回最相关的文档。那么什么是稀疏向量呢?简单说就是大部分维度为 0 的向量。简单举个例子来理解,假设有个词表(vocabulary):- TF-IDF(Term Frequency - Inverse Document Frequency):在词频的基础上加入“逆文档频率”因素,降低常见词的权重,提高稀有词的权重。
- BM25:一种改进的 TF-IDF 加权方案,同时考虑了词频饱和、文档长度归一化等因素,广泛应用于现代搜索引擎。
稠密文本检索(Dense Retrieval)
原理是通过神经网络(如 Word2Vec、BERT)将查询和文档分别编码成低维稠密向量(Dense Vector),使用向量相似度(如内积或余弦相似度)进行匹配,返回最相关的文档。那么什么是稠密向量呢?和稀疏向量刚好反过来了:稠密向量是所有维度基本都有值的向量。每一维都用浮点数表示,通常没有“0”或者很少有“0”。 这边的低维是相对于前面稀疏文本里的稀疏向量通常是极高维度的,因为那边的向量维度=词表大小,通常可以词表可以达到几十万甚至百万维,但是在稠密向量里,通常几十维到几千维的程度,所以是低维稠密向量。 举个例子,还是前面这句话: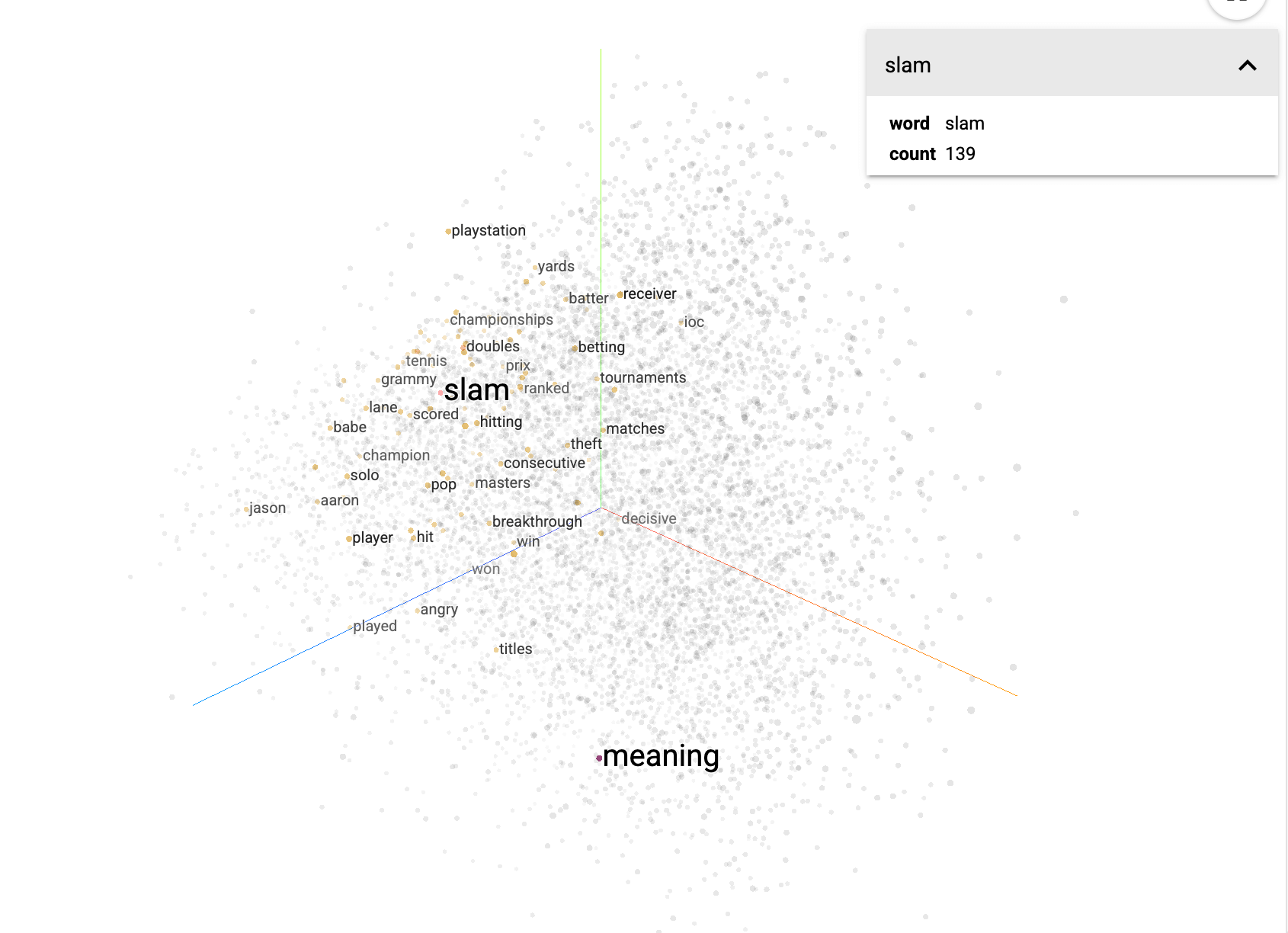
| 方法 | 模型类型 | 核心思路 | 优势场景 | 主要限制 | 计算成本 |
|---|---|---|---|---|---|
| DPR | Bi-Encoder(稠密单向量) | 把 query 和文档各自编码成向量,用相似度匹配 | 快速大规模召回,OpenQA | 语义粒度粗糙,难处理复杂约束 | 低 |
| Contriever | Bi-Encoder(稠密单向量,无监督) | 不依赖标注,用对比学习学通用向量 | 跨领域、无标注场景 | 精度有限,仍是单向量 | 低 |
| Cross-Encoder | Joint Encoder(交叉) | 拼接 query+文档一起输入模型,输出相关性分数 | 精排,语义理解最强 | 不可扩展,每对都要算一次 | 高 |
| ColBERT | Multi-Vector(Late Interaction) | 文档保留 token 向量,query token 按词找匹配 | 精排,兼顾效率与细粒度 | 存储大,对 query 表述敏感 | 中 |
| SPLADE | Sparse+Neural | 输出稀疏向量,结合倒排索引 | 适合搜索引擎,能用现有基础设施 | 稀疏,语义能力有限 | 中 |
融合方法(Hybrid Retrieval)
两者各有优缺点,因此很多系统或者应用场景会将两者进行结合,比如用稀疏检索(如 BM25)结合稠密检索先召回 Top K 文档,再用重排模型(Dense Reranker,如 Cross-Encoder)对结果进行重新排序,重新排序 引用一张我之前发的关于 Bi-Encoder 和 Cross-Encoder: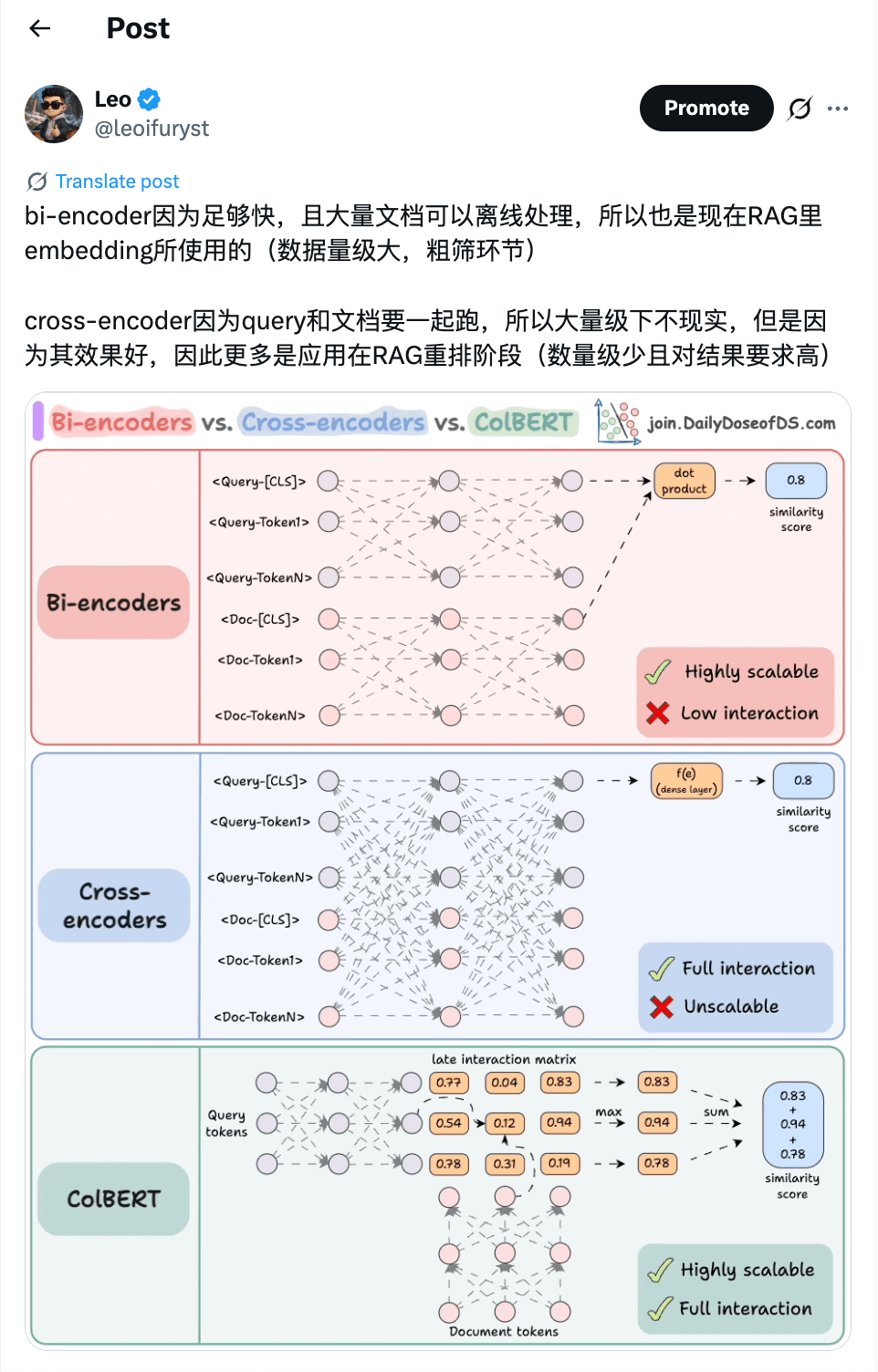
5.2 RAG 进阶
常规的 RAG 相对简单,在实际应用中,我们会在原本的架构之上,去运用一些技术和方法来提高,比如:- 标量 + 向量:通常 RAG 是将文档分块(Chunk)后向量化(Embedding)入库,然后查询也向量化后到向量数据库进行相似性搜索。如前面提到,实际上还可以结合传统的数据库或者 ES 进行标量数据的匹配检索,最后可以得到标量 + 向量数据。
- 重排(Reranking):不管是单向量还是结合了标量,在送到模型前可以用一些手段对文档进行重新排序,通常我们会使用重排模型对文档再进行评分排序,这样可以选择实际送到模型的文档
- 多跳 RAG:当单跳查询无法满足复杂的查询时,结合多跳是可以达到更好的效果的。
- 图增强 RAG(Graph-RAG):结合图的能力来扩展 RAG 的能力,尤其是在文档处理阶段,可以利用图 + 大模型来细化一些实体和关系,甚至进一步形成社区或领域的形态。
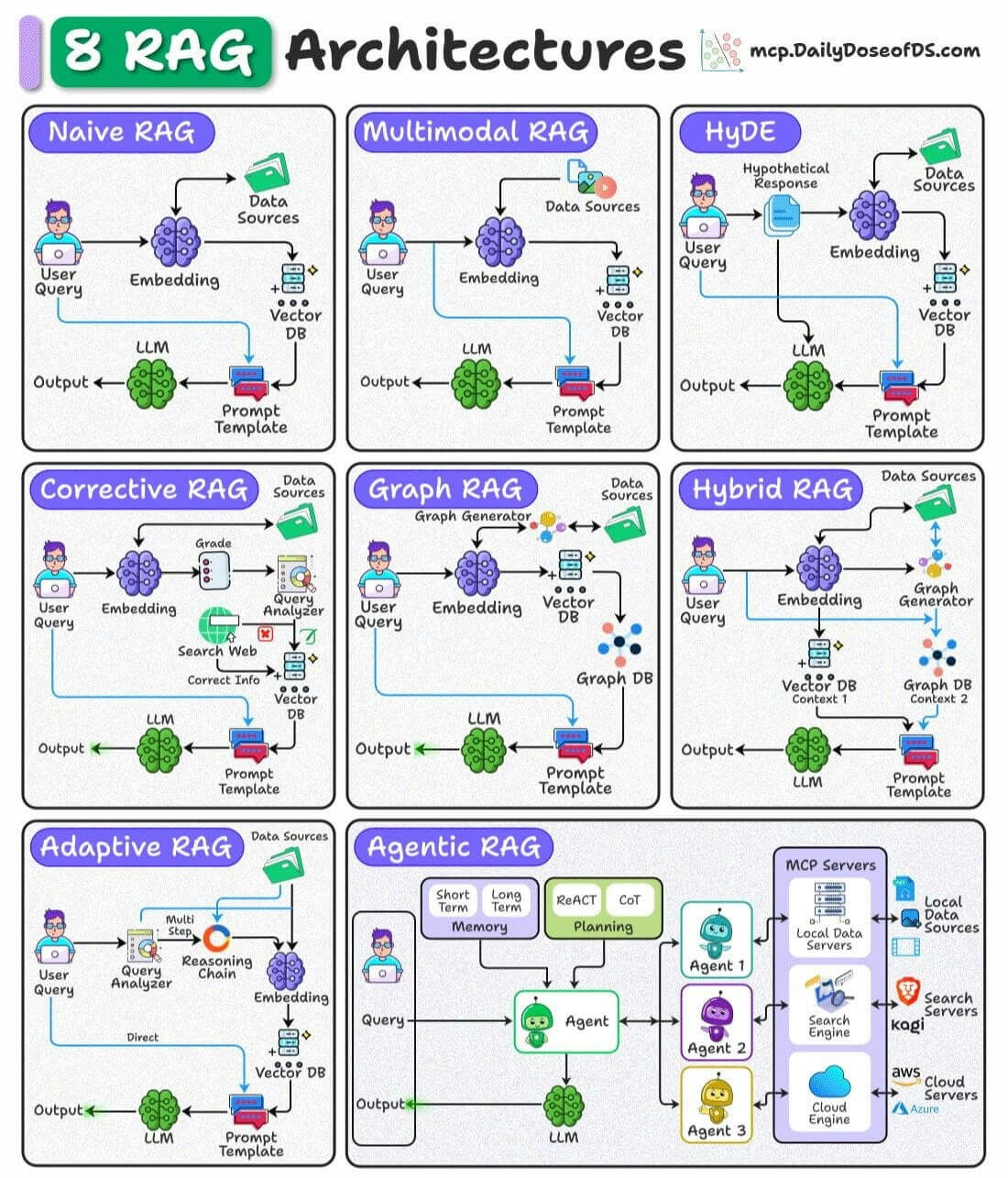
| 范式(Paradigm) | 关键特性(Key Features) | 优势(Strengths) |
|---|---|---|
| 基础RAG(Naïve RAG) | - 基于关键词的检索(如 TF-IDF、BM25) | - 实现简单易用 - 适合处理基于事实的查询 |
| 进阶RAG(Advanced RAG) | - 稠密向量检索模型(如 DPR) - 神经排序与重排序 - 多跳检索 | - 检索精度高 - 上下文相关性更强 |
| 模块化RAG(Modular RAG) | - 混合检索(稀疏 + 稠密) - 工具与 API 集成 - 可组合的领域特定流水线 | - 高度灵活、可定制 - 适用于多样化应用场景 - 具备良好可扩展性 |
| 图RAG(Graph RAG) | - 融合图结构 - 多跳推理 - 基于节点的上下文增强 | - 具备关系推理能力 - 可缓解幻觉生成 - 适用于结构化数据任务 |
| 智能体RAG(Agentic RAG) | - 自主智能体 - 动态决策能力 - 迭代优化与流程改进 | - 可适应实时变化 - 适合多领域任务的扩展 - 精度表现优异 |
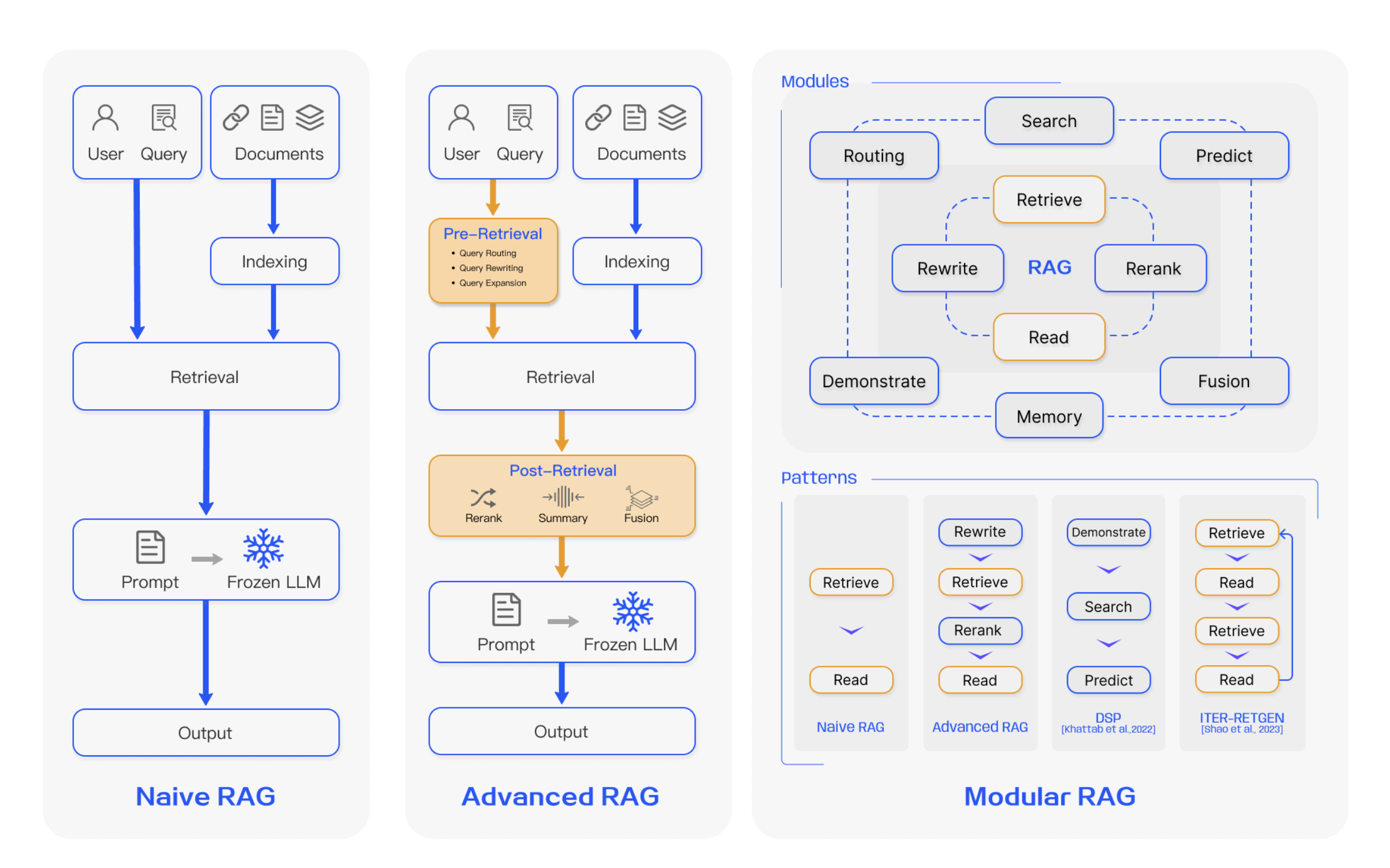
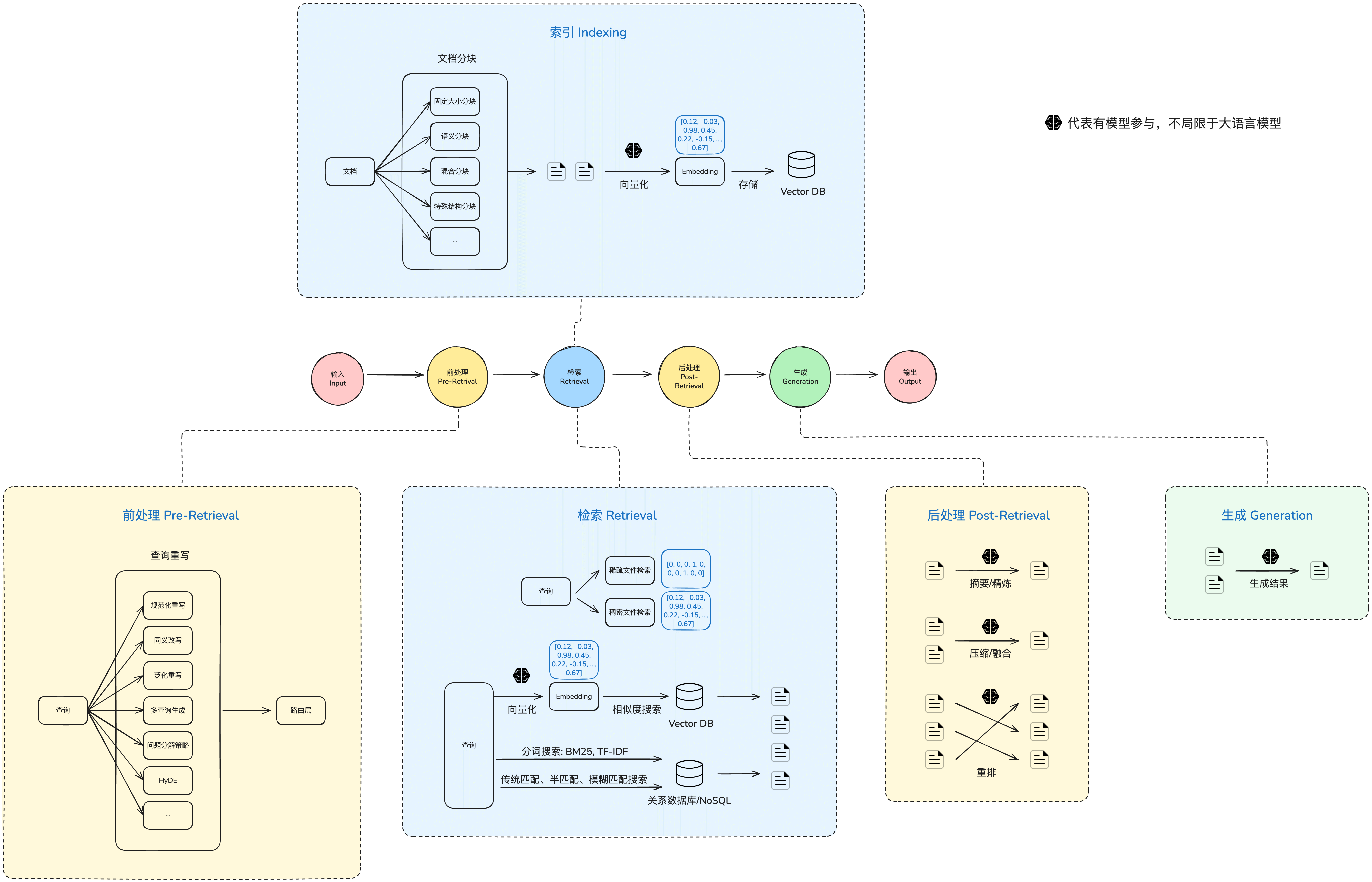
- 输入:可能有不同的输入方式,主流常见的是从 Chat 进来的问题
- 前处理:检索前作一些前置处理动作,目的是增加召回效果
- 检索:执行检索
- 后处理:对检索的结果进行特定的处理,目的也是增加召回效果
- 生成:给大模型输出最后的结果
- 输出:将结果返回
5.2.1 查询重写
在传统的 RAG 里,通常就是将查询通过向量化的手段转成嵌入(embedding),做相似性搜索后给到大模型。这种情况下有明显可见的问题:输入查询无法顺利匹配到文档块。 在实际场景下,用户输入的问题有可能因为过于简化或者表述不当而无法通过相似度搜索匹配到合适的文档块,使得最终的效果不符合预期。面对这个问题,可以应用查询重写来进一步缓解并提升效果。 正如前面提到的,重写策略其实有挺多的,目前主流的有这么几种(更多还是一些类别的划分,实际上在不同的业务场景下还会有不同的策略浮现的,比如一些行业词汇重写、黑白词等等,这边就不过度展开):- 规范化重写(Canonicalization):将随意、模糊、口语化表达转成标准清晰的问题
- 同义改写(Paraphrasing):增强表达覆盖、抗 embedding 漏召
- 泛化重写(Step-Back Query):提升复杂问题检索效果
- 多查询生成(Multi-query Generation):多视角覆盖、提升召回率
- 问题分解策略(Question Decomposition):将复杂查询拆分为多个子问题,分步检索和推理
规范化重写(Canonicalization)
规范化重写其实就是针对查询问题让大语言模型帮忙进行重写,使得问题更加规范化,这其中有一些不同的手法。我们先来看一个基础的示例:同义改写(Paraphrasing)
同义改写的原理也是差不多的,对于不合适的表述,可以进行同义替换改写,使得输入的内容可以更容易匹配到合适的文档块。比如:泛化重写(Step-Back Query)
泛化重写是把具体的问题抽象,将问题覆盖范围扩大了,这样可以扩大检索范围和获取更完整的上下文信息,比如:多查询生成(Multi-query Generation)
这个方式也是应对用户问题表述不清晰或含糊的情况,通过将单一问题生成多个问题的方式,对一个问题提供多个角度,这样可以提高覆盖度,达到更好的检索和结果生成效果。 我们来看下例子:问题分解策略(Question Decomposition)
将一个复杂问题拆解成多个原子问题,使得可以基于多个问题去分别召回文档块,比如:5.2.2 检索结果重排
重排是提升 RAG 检索效果里很重要的一步,也是目前实际应用中很广泛被采用的一种方式,主要有几种方式:- 基于打分函数的传统重排方法:BM25,TF-IDF 余弦相似度
- 语义匹配类重排方法:双塔结构(Bi-Encoder),交叉编码器(Cross-Encoder)
- 生成式重排方法:通过 LLM 进行评分和排序
retriever,构建 ContextualCompressionRetriever,里面会使用 FlashrankRerank

- Document 1 -> Document 1
- Document 4 -> Document 2
- Document 6 -> Document 3
5.2.3 Graph RAG

索引阶段
看看架构图可以有个全局的认知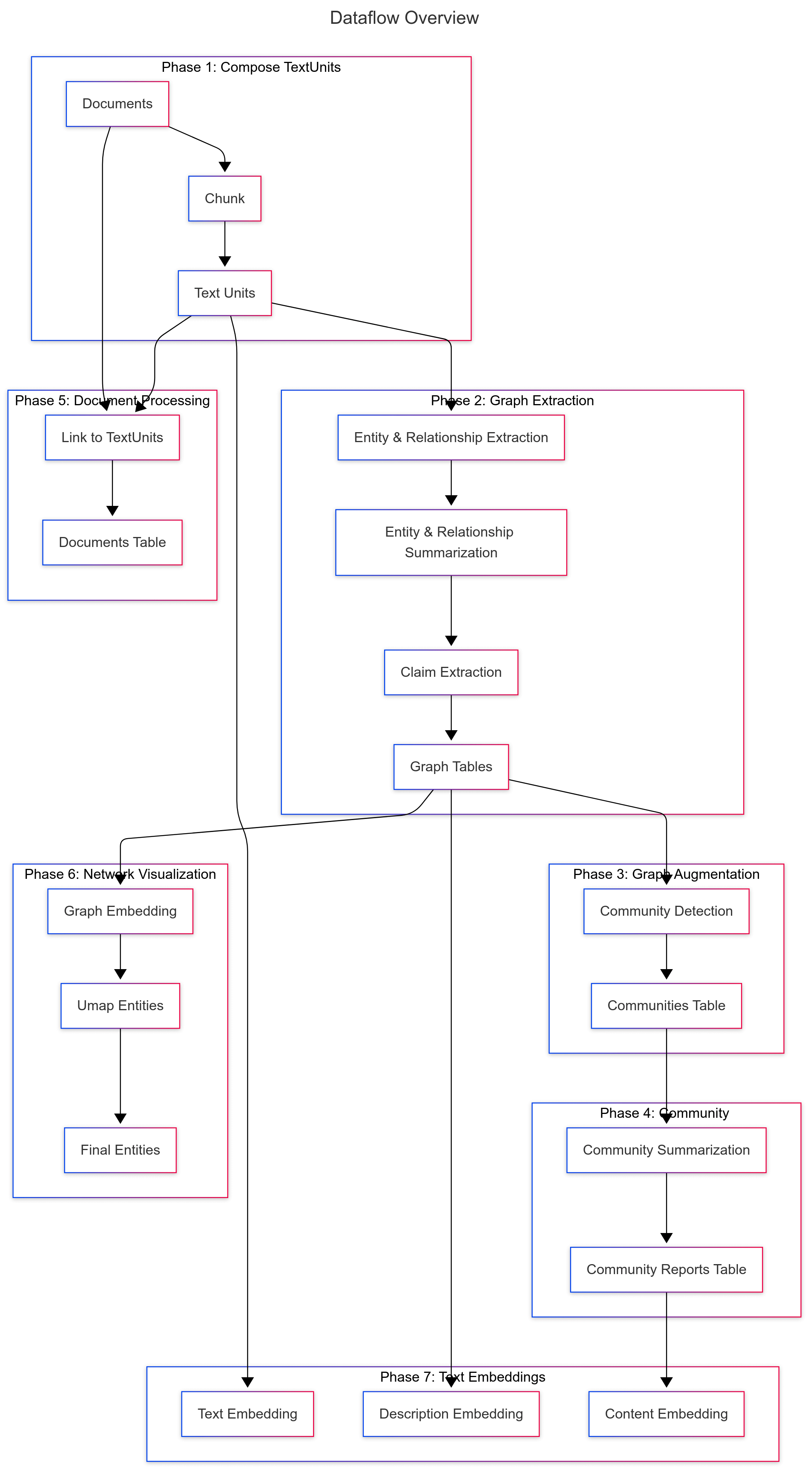
- 文本处理 (Text Processing)
- 文档处理(Document Processing)
- 图提取(Graph Extraction)
- 图增强(Graph Augmentation)
- 声明提取(Claims Extraction)
- 社区创建(Community Creation)
- 文本单元最终化((Final Text Units)
- 社区报告生成(Community Reports)
- 文本嵌入(Text Embeddings)
文本处理 (Text Processing)
主要接收多种数据输入,然后对输入的数据进行切分(支持按句子或者 token 进行切分),分块得到文本单元 TextUnits。 这步主要是为了方便后续的数据处理,因为后续的处理涉及多轮次的模型调用,以一个合理块大小的处理单元来处理,会更加方便且上下文不容超过,也适合并发调度处理。文档处理(Document Processing)
将文本处理阶段处理出来的 TextUnits 与原始文档建立引用关系,形成一个结构化的数据表,用于后续一些操作:- 跟踪每个文档包含哪些 chunk
- 后续社区摘要、图构建等流程中使用
- 统一文档展示和可视化索引
图提取(Graph Extraction)
会包含几个阶段:- **实体(Entity)和关系(Relationship)**提取
- 图数据进行摘要简化(Graph Summrization)
图增强(Graph Augmentation)
图增强里主要是图最终化,也就是将初步提取出来的图数据(实体节点和关系边),经过清洗、加工、标准化并准备好用于下游使用的过程。因为这是图构建的最后阶段:- 之前:只有基础的实体名称、描述、关系
- 之后:实体具备了向量表示、空间坐标、网络属性等完整特征
- 根据配置决定是否创建向量(embedding)
- 根据配置决定是否对图做 UMAP 或其他布局(layout)方法,生成 2D/3D 坐标用于可视化
- 计算每个实体节点的度数(degree),用于后续分析或排序
- 合并、移除重复、预填充缺失字段、生成唯一 id 等等
UMAP(Uniform Manifold Approximation and Projection)中文名为统一流形近似与投影算法,是一种非线性降维算法,可以用于把高维数据(比如向量嵌入 embedding)映射到二维或三维空间,用于方便可视化或聚类分析。简单说就是: UMAP 是一种可以把高维“云雾向量”压缩成漂亮二维坐标点的方法,保留结构、方便展示和聚类关于实体节点的度数(degree),其实是每个节点连接的边的数量,比如:
- Leo —写—> 书
- Leo —开发—> 应用
- 找到重要节点:高度数可能表示实体在图中很核心
- 控制布局:在图布局中(比如 UMAP 或 Force-directed),高 degree 节点更可能在中心。
- 下游模型特征:在图神经网络中,degree 是常用的节点特征之一
- 图过滤:有时我们只保留 degree>=2 的节点,忽略孤立点(degree=0)。
声明提取(Claims Extraction)
Graph RAG 里面是叫做共变量(Covariates)提取任务,一个道理,就是从文本单元里提取声明(Claims)的过程,并将其转换为结构化数据,供后续图构建或社区摘要使用。 操作主要是让模型针对文本单元里的内容进行声明提取,Prompt 里会包括实体、想找的主张,需要分析的原始内容,最终模型会输出声明主体、涉及对象、声明类型、声明状态(对/错/存疑)、时间范围、描述说明、原始文本这些信息。社区创建(Community Creation)
这里会借助 Leiden 算法将节点进行社区化,简单说就是把相似、相关的阶段放到统一个社区。社区是指内部连接多,外部连接少的一组节点,类比班级,一个班级内部的同学联系较为紧密,而不同的班级之间的联系相对就少一点,这里班级就是一个社区的概念。另外同一个班级之下还可以分兴趣小组,这样就出现了分层级的社区,也就是某个社区有可能归属于某个父社区。Leiden 算法整体就是在做这么一件事情,我们不展开算法的细节,有兴趣的可以自行了解。 通过构建,最终是可以得到一个这种结构的数据文本单元最终化((Final Text Units)
这一步主要是针对前面的几个步骤产生的中间数据做最终的聚合关联,也就是将文本单元(TextUnits)与实体(Entities)、关系(Relationships)和声明共变量(Covariates)。关联之后文本单元就拥有了实体 id 列表、关系列表、声明列表。 大概数据如下:社区报告生成(Community Reports)
这步核心目的是基于实体(Entities)、关系(Relationships)、社区(Communities)和声明(Claims),构建每个社区的摘要性报告。 核心的处理步骤有:- 社区展开:将社区结构展开
- 数据准备:预处理实体、关系和声明数据
- 上下文创建:为每个社区构建上下文
- 摘要生成:生成社区报告
文本嵌入(Text Embeddings)
这步是最后的环节了,用于为前面产生的各种文本内容生成对应的向量表示,用于后续检索阶段的语义搜索和向量检索。主要包括:- 完整文档内容
- 实体标题和描述
- 关系描述
- 文本单元
- 社区标题和摘要
- 社区完整报告内容
检索阶段
Graph RAG 针对不同的使用场景,提供了 4 种查询方法:- 全局搜索(Global Search):面向社区报告级别的全局搜索,适合高层知识查找
- 本地搜索(Local Search):走了图和文本搜索,同时融合实体、关系、文本等细粒度搜索
- 动态推理搜索(DRIFT Search):和本地搜索类似,但是引入了 embedding 对齐
- 基础搜索(Basic Search):走了文本级别的搜索,是最轻量的文本向量语义检索
全局搜索(Global Search)
主要基于社区(Community)和其报告(Reports)进行粗粒度搜索。走的是 Map Reduce 的方式,也就是将社区报告拆成多个文本块(chunks),每个文本块分别发送给大语言模型做分析,会生成类似下面格式的内容本地搜索(Local Search)
本地搜索会利用向量搜索去检索出合适的实体(Entities),然后给予这个实体去构建对应的上下文,其中涉及到了以下的数据:- 实体
- 关系
- 文本单元
- 社区摘要
- 声明