2.1 上下文窗口限制与问题分类
2.1.1 长上下文 ≠ 好上下文
上下文窗口
要了解和学习上下文工程, 首先需要理解上下文窗口。我们先来看下面这个表:| 模型 | 上下文窗口 |
|---|---|
| GPT-5 | 400,000 |
| gpt-oss-120b | 131,072 |
| GPT-4o | 128,000 |
| Gemini 2.5 Pro | 1,000,000 |
| Claude Sonnet 4 | 1,000,000 |
| Claude Opus 4.1 | 200,000 |
- 上下文太长,超过上下文窗口限制
- 上下文太短,不足以支撑推理
- 上下文很长,但是还没超过上下文窗口限制
- 上下文适中
从长度到语义
上面是基于上下文长短来进行分类的,但是实际上上下文工程里遇到的问题不是这么简单的问题,还有更深层的问题, 因为上下文说到底还是自然语言的范畴,是为了让大模型更容易理解背景信息和目标而提供的内容,因此其实我们海英个进一步关注上下文遇到的问题。Drew Breunig 在这篇文章中提出了四个定义:- 上下文污染(Context Poisoning):幻觉等错误进入上下文,被模型反复引用,导致持续的错误
- 上下文分心(Context Distraction):上下文太长,模型反而忽略了训练中学到的东西
- 上下文混淆(Context Confusion):无关的上下文被模型用来生成低质量回答
- 上下文冲突(Context Clash):上下文中的不同信息或工具互相矛盾
- 信息污染(Information Poisoning):错误信息持续留在上下文中,其实不局限于当前的上下文,这个信息污染是有可能从运行时的上下文外溢到外部存储的,比如长短期记忆,或者一些 Specification。容易造成重复错误行为、目标偏离和行为死循环。
- 注意力偏移(Attention Misalignment):上下文长度增加会导致效果变差,其中的核心是上下文分心,模型被上下文分散了注意力,并且还会进一步让注意力从目标或指令转向无关的上下文,容易造成忽略指令、回答随机和无法聚焦。
- 语义冲突与混乱(Semantic Conflict & Confusion):上下文存在歧义、矛盾或冗余等情况,导致模型难以理解和识别,导致最终效果不符合预期。容易造成误解、矛盾回答和答非所问。
2.1.2 常见问题分类
信息污染(Information Poisoning)
信息污染(Information Poisoning) 是在上下文中充满了各种数据,尤其是在 Agent 这种复杂环境下,容易产生很多相关和不相干的数据。随着时间的推移,上下文就会堆积各种数据,当以 Transformer 的注意力机制驱动的大模型在推理的时候,就会导致被大量不相关的内容分散注意力,此时就会导致效果的下降。 这里面比较严重且突出的问题是上下文污染(Context Poisoning),或者也可以称为上下文投毒。Gemini 2.5 技术报告里描述了 Gemini 2.5 Pro 被用来作为 Agent 自主通关了宝可梦游戏,这份报告主要展现了 Gemini 2.5 Pro 的长上下文推理和多步任务规划能力,能够解决复杂迷宫、道具获取、战斗策略等问题。里面有一部分值得我们注意的,就是关于在处理超长历史时偶尔会陷入重复行为或幻觉,在部分情境下会很出现目标混淆或策略固执等问题。文中有一段是这样描述的:Fixations on delusions due to goal-setting and also due to the Guidance Gemini instance are not an uncommon occurrence in watching Gemini Plays Pokémon - the TEA incidence is hardly the only example of this behavior. An especially egregious form of this issue can take place with “context poisoning” – where many parts of the context (goals, summary) are “poisoned” with misinformation about the game state, which can often take a very long time to undo. As a result, the model can become fixated on achieving impossible or irrelevant goals. This failure mode is also highly related to the looping issue mentioned above. These delusions, though obviously nonsensical to a human (“Let me try to go through the entrance to a house and back out again. Then, hopefully the guard who is blocking the entrance might move.”), by virtue of poisoning the context in many places, can lead the model to ignore common sense and repeat the same incorrect statement. Context poisoning can also lead to strategies like the “black-out” strategy (cause all Pokémon in the party to faint, “blacking out” and teleporting to the nearest Pokémon Center and losing half your money, instead of attempting to leave).翻译成中文是
在观看 Gemini 玩《宝可梦》的过程中,常常会看到因为设定目标或受到”指导版 Gemini 实例”的影响而产生的执念式妄想,这并不是个别现象,TEA 事件也只是其中一个例子而已。其中一种更严重的情况被称为”上下文污染”(context poisoning)——即大量关于游戏状态的错误信息被写入到上下文中(包括目标设定、总结等部分),这类污染往往需要很长时间才能纠正。一旦发生这种情况,模型可能会执着于实现一些根本不可能或毫无意义的目标。这种错误还常常伴随着”死循环”现象。尽管这些行为对人类来说明显是荒谬的,比如模型可能会不断尝试”进出一座房子,希望门口的守卫因此移动位置”,但由于上下文中的错误信息大量存在,它会使模型忽视常识,不断重复错误的判断。上下文污染甚至会导致模型采取一些极端策略,比如所谓的”黑屏策略”:故意让队伍中所有宝可梦全部昏迷,从而”黑屏”被传送回最近的宝可梦中心,同时损失一半的钱,而不是尝试正常离开当前区域。也就是在上下文过长的情况之下,因为一些错误或者不合适的信息混杂在上下文并且一直持续存在于上下文中,导致 Agent 可能不断重复做出错误的决策或举动,这个负面效果需要经历较长的时间,这个时间就是对应的信息慢慢从上下文中淡化或者消失的过程。 因此上下文窗口大小在现在这个发展阶段仍是一把双刃剑,而不是银弹,也就是意味着更大的上下文不一定是最好的选择,还是要取决于具体的使用场景和上下文工程策略来决定,因此不要盲目追求大上下文窗口和超长上下文的组装,那样有可能让结果恶化,并且这个不一定在开发阶段能感知到,很有可能是一个较为隐蔽不好观测的一个情况。 之前我也分析过,Manus 分享的这篇 AI Agent 的上下文实践的文章中提到,AI Agent 实践中使用少样本提示(Few-Shot)需要谨慎:
Language models are excellent mimics; they imitate the pattern of behavior in the context. If your context is full of similar past action-observation pairs, the model will tend to follow that pattern, even when it’s no longer optimal. This can be dangerous in tasks that involve repetitive decisions or actions. For example, when using Manus to help review a batch of 20 resumes, the agent often falls into a rhythm—repeating similar actions simply because that’s what it sees in the context. This leads to drift, overgeneralization, or sometimes hallucination.翻译成中文是:
Few-shot 提示是一种常见的技术,用于提升大语言模型(LLM)的输出质量。但在智能体(agent)系统中,它有时却会在不经意间带来反效果。 语言模型擅长”模仿”,它们会学习和复刻上下文中呈现的行为模式。如果你提供的上下文里充满了相似的”动作—观察”对,模型往往会机械地遵循这些模式,即便这些行为已经不再是最优选择。 在需要重复决策或执行操作的任务中,这种问题尤为明显。比如,当使用 Manus 帮助审阅一批共 20 份简历时,智能体很容易陷入”节奏”中——重复执行同样的操作,只因为它在上下文中看到类似的例子。这种现象会导致”漂移”、过度泛化,甚至出现幻觉(hallucination)。大模型倾向于模仿,因此如果提供的样本是规律重复的,就会导致模型倾向于模仿样本,导致后续的行为不断重复。尤其当你把模型先前的响应结果一起带入到新一轮推理中时,就可能造成结果偏差。模型会误以为”你希望我继续往这个方向走”,久而久之形成错误的趋势。

The fix is to increase diversity. Manus introduces small amounts of structured variation in actions and observations—different serialization templates, alternate phrasing, minor noise in order or formatting. This controlled randomness helps break the pattern and tweaks the model’s attention. In other words, don’t few-shot yourself into a rut. The more uniform your context, the more brittle your agent becomes.中文是:
解决方法是引入更多的多样性。Manus 通过在动作和观察中加入少量有结构的变化来实现这一点——比如使用不同的序列化模板、替换措辞、在顺序或格式上加入细微扰动。这种”可控的随机性”有助于打破固定模式,重新调整模型的注意力焦点。 换句话说,别让 few-shot 提示把你困在一种套路里。上下文越单一、越一致,你的智能体就越脆弱。也就是通过一定得刻意微调,避免大模型陷入一个循环圈套里,这是一个小技巧。 无论是 Gemini 在游戏中陷入错误幻觉与循环,还是 Agent 因少样本提示而产生重复行为,背后都体现了同一个风险:当上下文中充斥了不相关、误导性强或错误的信息时,大模型容易产出错误倾向的结果。并且这种错误倾向无法在短期内被快速纠正,通常需要有检测和预防机制才可有效缓解和进一步解决这类问题。
注意力偏移(Attention Misalignment)
虽然上下文空间的长度已经拉到了 1M 的 Tokens 数,但是实际我们在应用中,为了保持好的效果输出,几乎不会撑满整个上下文空间,因为随着上下文的长度增大,最终的效果并不会持续正向提升,甚至有可能是降低的。因为大语言模型底层是以 Transformer 为主的注意力机制驱动的,过多的上下文会使注意力分散,这个在后续 Prompt 技术中我们也会了解到,类似 Claude Code 里会有保证不断回想之前计划的目标以便模型不断集中在目标的执行上。 因此注意力偏移(Attention Misalignment) 就是包括这一类问题,随着上下文长度增加,开始出现效果下降的现象。我们首先可以来看看 Chroma 的一篇技术报告,开篇提到了:Large Language Models (LLMs) are typically presumed to process context uniformly—that is, the model should handle the 10,000th token just as reliably as the 100th. However, in practice, this assumption does not hold. We observe that model performance varies significantly as input length changes, even on simple tasks.大模型通常被假设可以均匀处理上下文,比如处理第 10,000 个 token 的效果和处理第 100 个 token 一样可靠。实际上这个假设不成立,即便是简单任务,随着输入上下文长度的变化,模型的表现会出现显著差异。
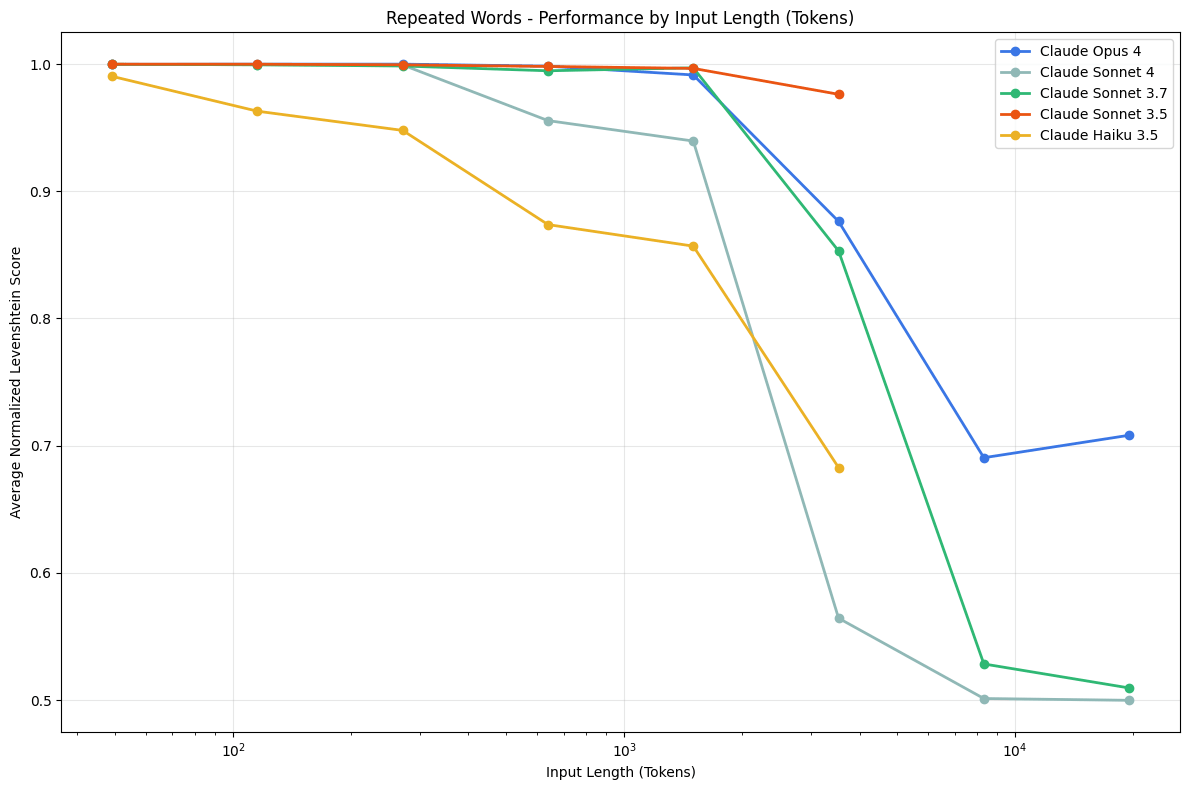
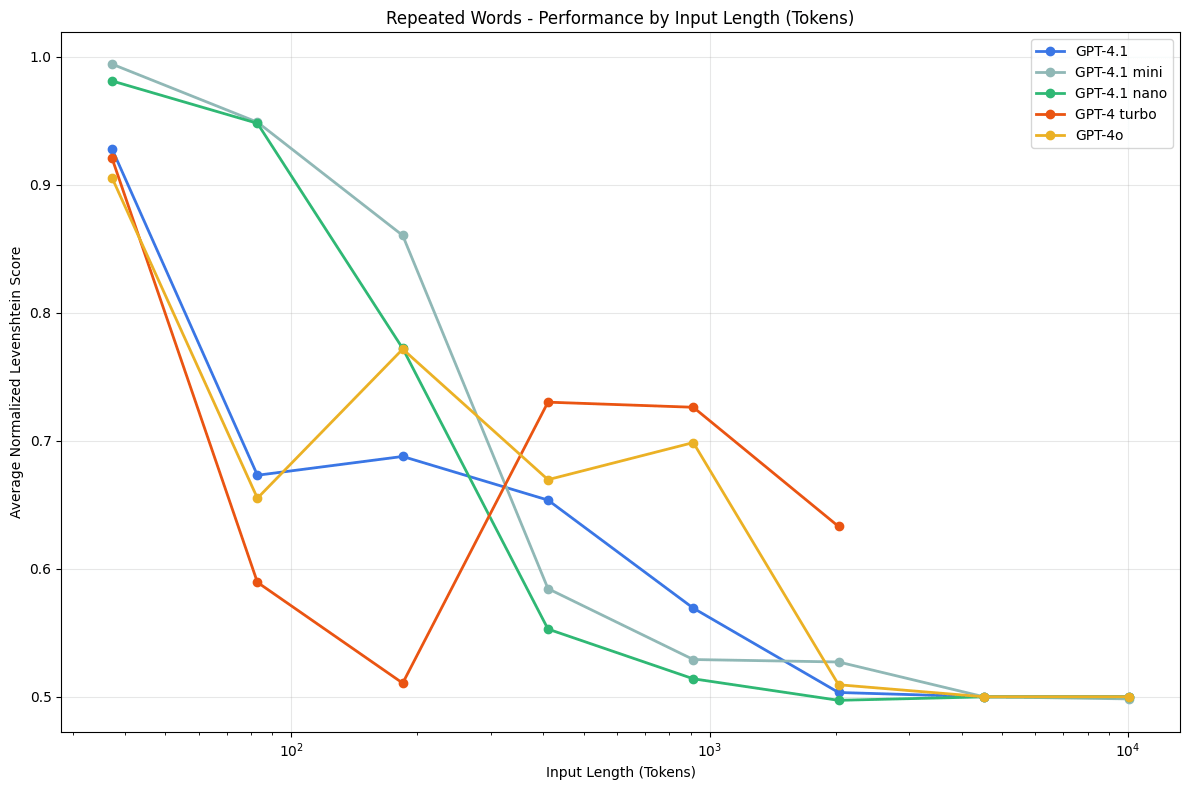
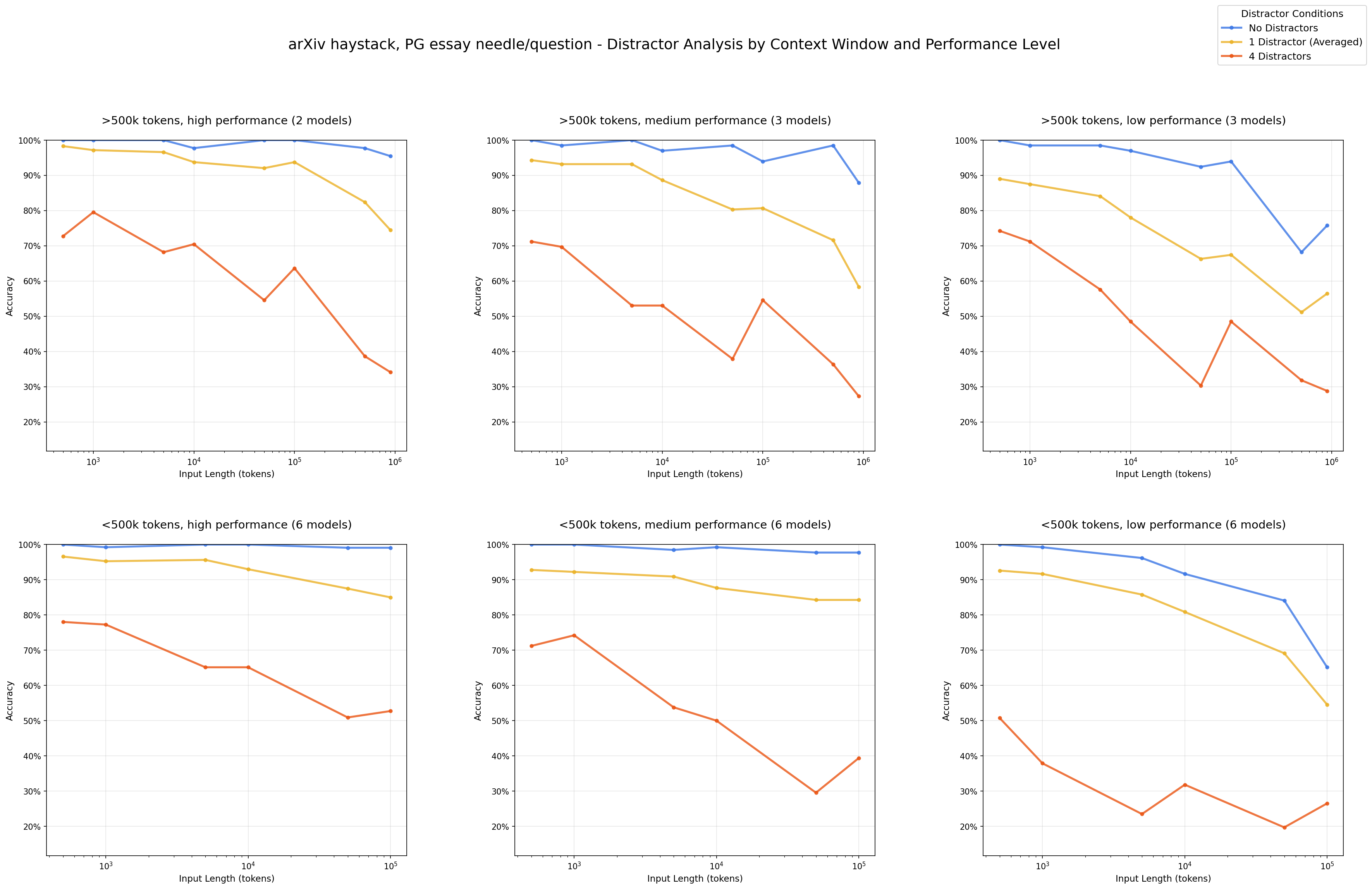
While Gemini 2.5 Pro supports 1M+ token context, making effective use of it for agents presents a new research frontier. In this agentic setup, it was observed that as the context grew significantly beyond 100k tokens, the agent showed a tendency toward favoring repeating actions from its vast history rather than synthesizing novel plans. This phenomenon, albeit anecdotal, highlights an important distinction between long-context for retrieval and long-context for multi-step, generative reasoning.翻译成中文是:
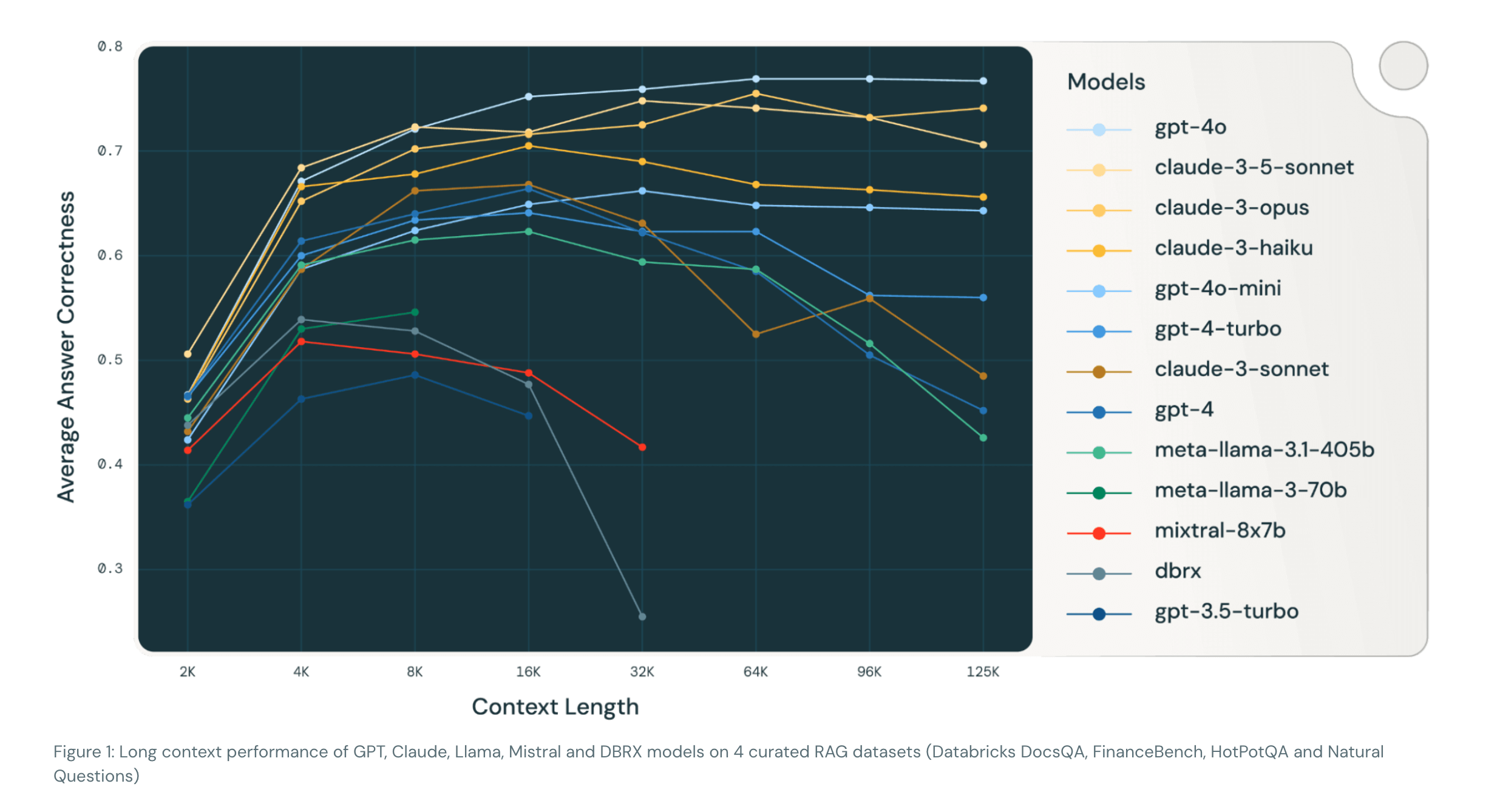
虽然 Gemini 2.5 Pro 支持超过 100 万个 token 的上下文,但如何在智能体(agent)系统中有效利用这一能力,仍是一个新的研究前沿。在这类 agentic 设置中,有观察发现:当上下文显著超过 10 万 token 时,智能体往往倾向于重复其历史中的动作,而不是生成新的计划。这种现象虽然仍属经验观察,但它揭示了一个重要的区别:长上下文在检索任务中的应用,与在多步生成式推理中的作用,其实并不相同。其实前面我们也有看到类似的情况了,也就是随着上下文不断累积,模型出现了不断重复一些动作,哪怕那些动作是错误的,为什么会出现这个情况呢?其实本质上就是因为模型过于关注上下文内容了,这其实也从另一个侧面说明了上下文之于模型推理的重要性,也间接说明了,如果我们构建的上下文是不合适的或错误的,那么对于模型的推理有可能起到副作用,这也是上下文工程中很重要的一点。 Databrcks 有一篇研究给出了一些有趣的结论:使用更长的上下文并不总能提升 RAG 的表现。
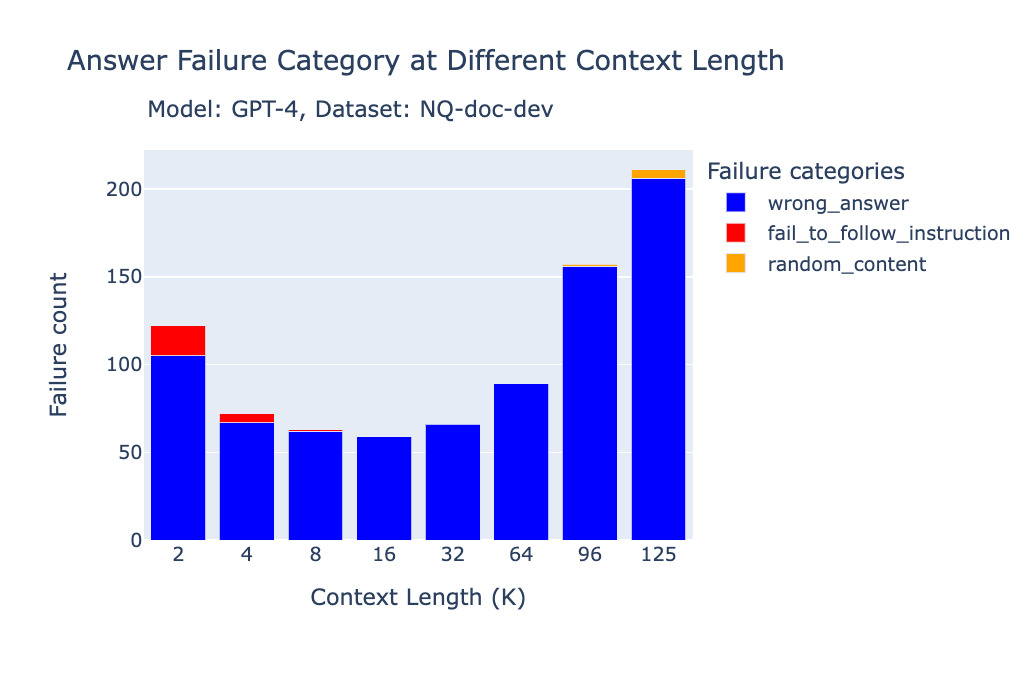
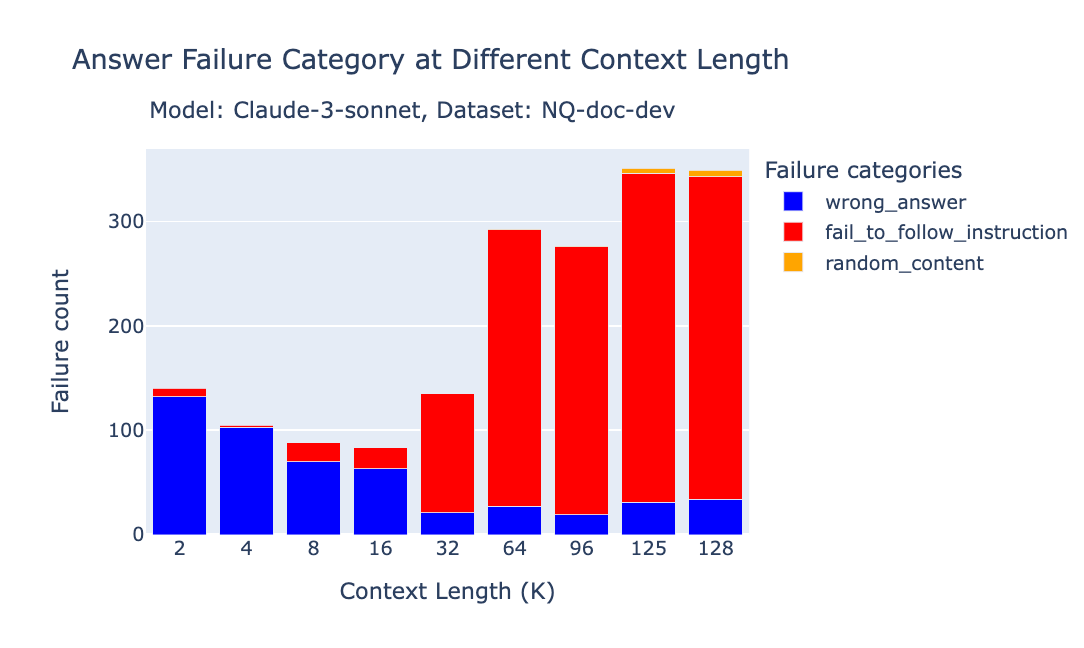
- 重复内容(repeated_content):当大模型的回答是完全重复的词语或字符(无意义的重复)。
- 随机内容(random_content):当模型生成的回答完全是随机的、与内容无关,或在逻辑或语法上不通顺。
- 未遵循指令(fail_to_follow_instruction):当模型没有理解指令的意图,或未按照问题中指定的要求作答。例如,指令要求根据给定上下文回答问题,而模型却去总结上下文。
- 错误回答(wrong_answer):当模型试图按照指令作答,但提供的答案是错误的。
- 其他(others):当失败情况不属于上述任何一种类别时使用。
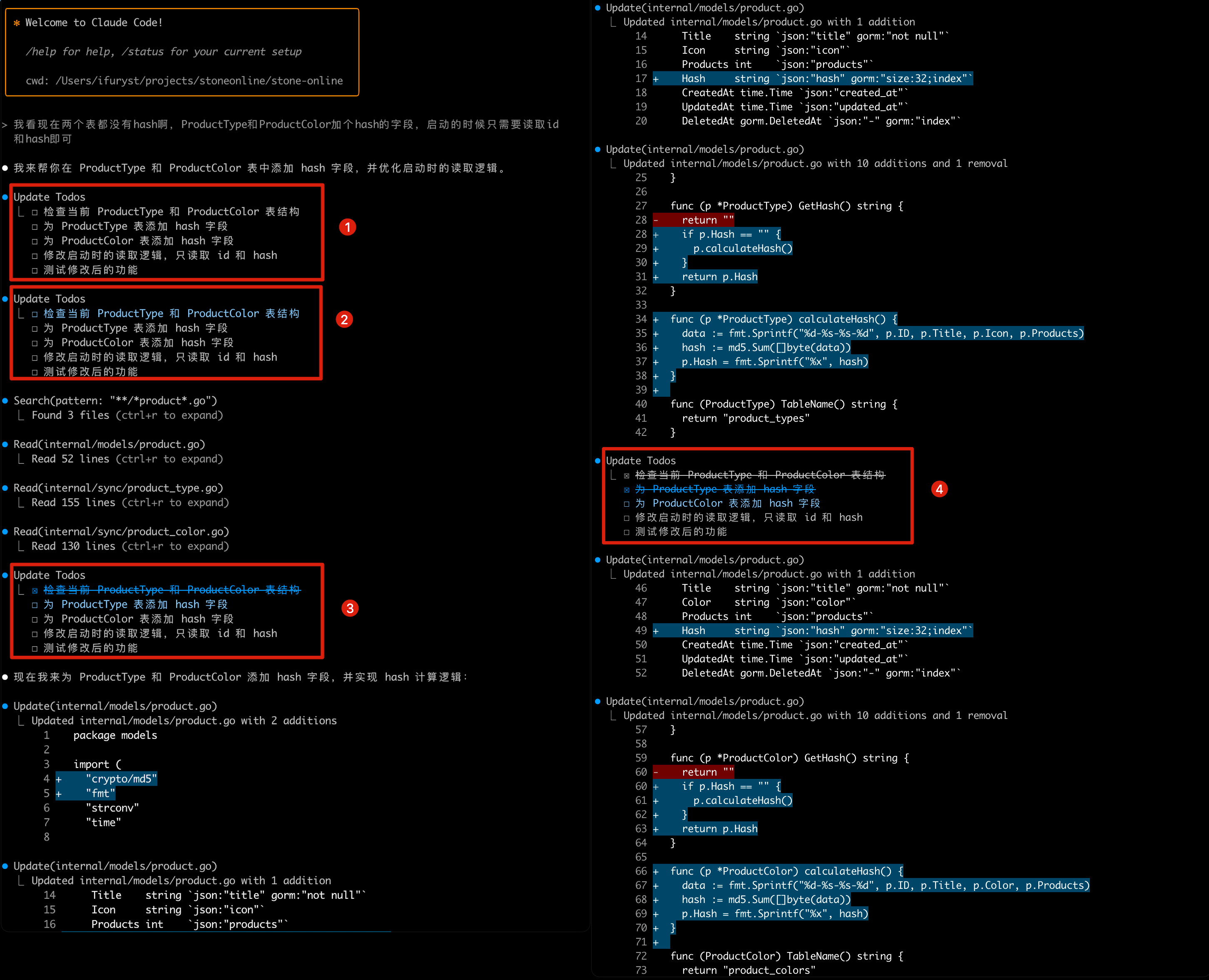
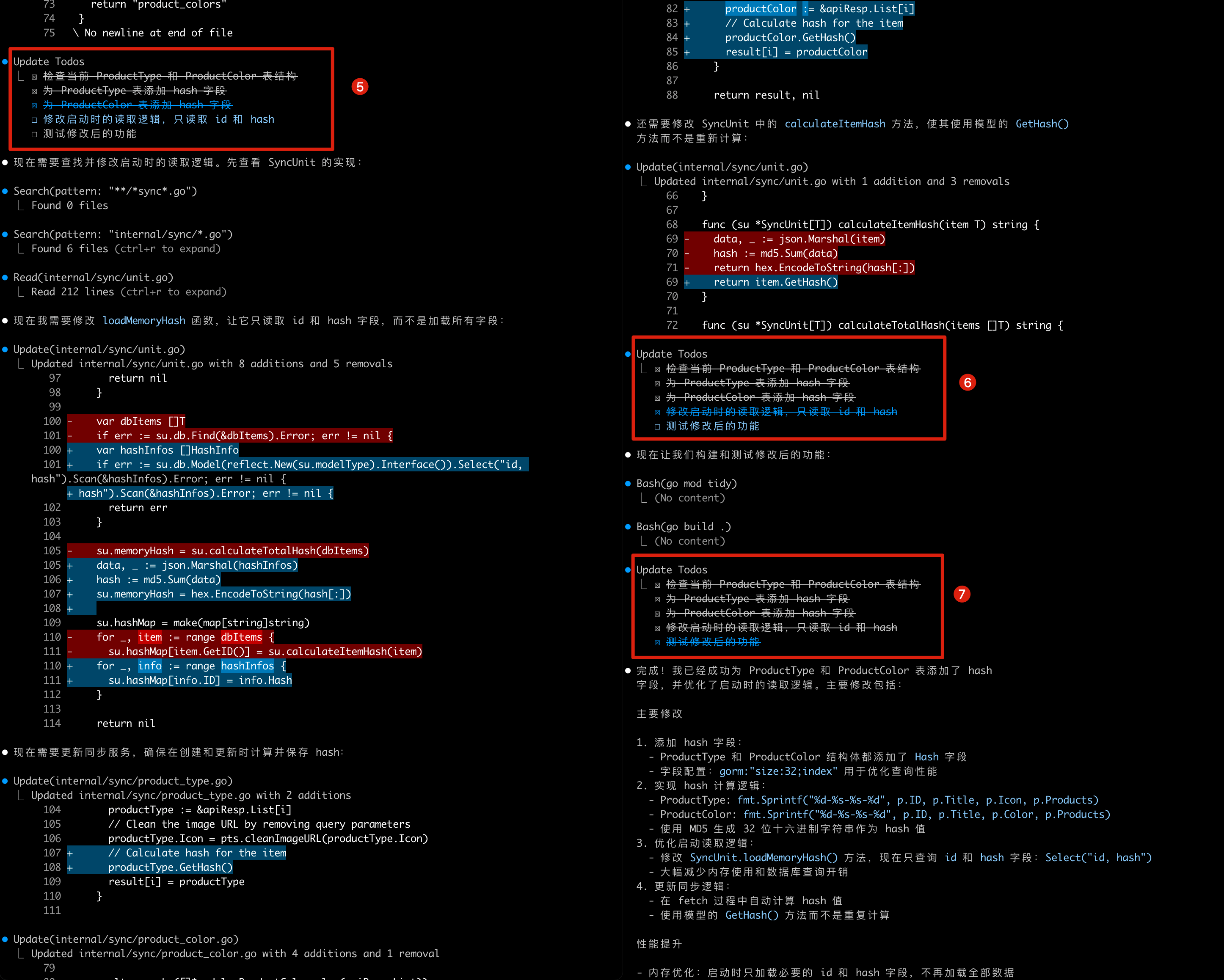

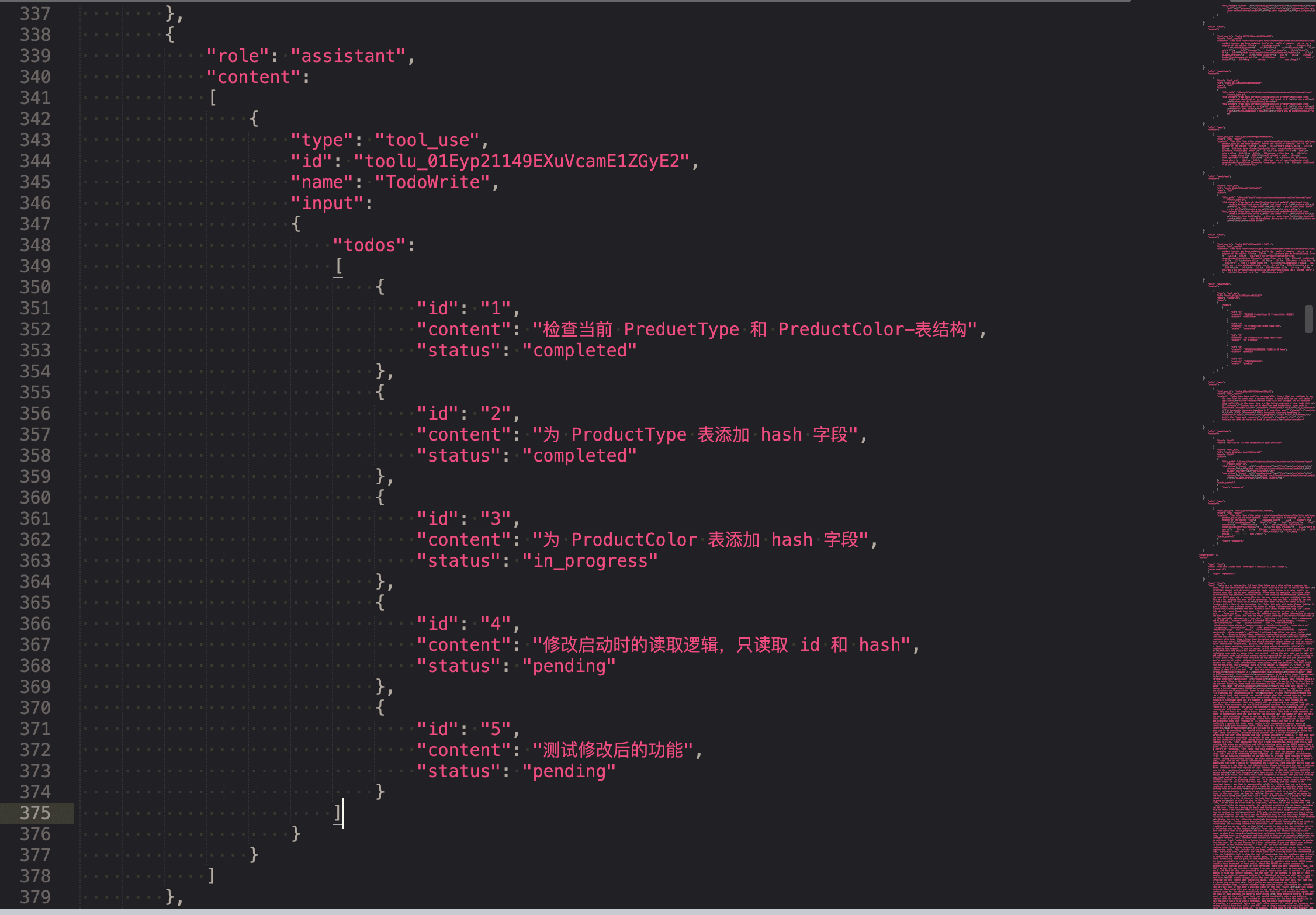

If you’ve worked with Manus, you’ve probably noticed something curious: when handling complex tasks, it tends to create a todo.md file—and update it step-by-step as the task progresses, checking off completed items. That’s not just cute behavior—it’s a deliberate mechanism to manipulate attention. A typical task in Manus requires around 50 tool calls on average. That’s a long loop—and since Manus relies on LLMs for decision-making, it’s vulnerable to drifting off-topic or forgetting earlier goals, especially in long contexts or complicated tasks. By constantly rewriting the todo list, Manus is reciting its objectives into the end of the context. This pushes the global plan into the model’s recent attention span, avoiding “lost-in-the-middle” issues and reducing goal misalignment. In effect, it’s using natural language to bias its own focus toward the task objective—without needing special architectural changes.中文是:
如果你用过 Manus,可能会注意到一个有趣的现象:在处理复杂任务时,它常常会创建一个 todo.md 文件,并在任务执行过程中逐步更新,勾选已经完成的项目。 这并不是一种”可爱”的行为,而是一种有意设计的注意力操控机制。 Manus 处理的典型任务平均需要调用大约 50 次工具。这是一个非常长的执行链——而由于 Manus 的决策依赖 LLM,它在上下文很长或任务很复杂的情况下,容易出现跑题或忘记最初目标的问题。 通过不断地重写这份待办清单,Manus 实质上是在将任务目标”复述”到上下文的结尾处。这样做可以把全局计划强行推入模型最近的注意力范围,避免”上下文中段丢失”问题,同时减少目标偏移。换句话说,它是在用自然语言主动引导模型关注核心任务目标——无需修改模型结构,就能实现注意力的偏置。Manus 可以看作是和 Claude Code 相差不会特别大的 AI Agent 的产品,因此我们可以看到殊途同归,业界的实践方式都是相似的,你也可以在其他的 AI Agent 里看到同样的实践,目的都是为了让注意力不要产生偏移。 其实提示词技术(或者说上下文)在某种程度就是加强或者说提供一个遮罩层,这样可以对训练时获得的权重进行一定程度的补充,使得结果偏向于更正确的可能,但是某些情况下会导致模型分散了注意力。
语义冲突与混乱(Semantic Conflict & Confusion)
在多轮交互或复杂上下文环境中,语义冲突与混乱是影响大模型表现的重要隐患之一。它通常表现为:新引入的信息或工具与已有上下文中的内容产生矛盾,导致模型产生困惑、做出错误判断,甚至出现”随机选择”的不稳定行为 微软和 Salesforce 在一篇论文中展示了这样一个现象:将单轮次的交互拆成多轮次,会导致模型的效果显著下降。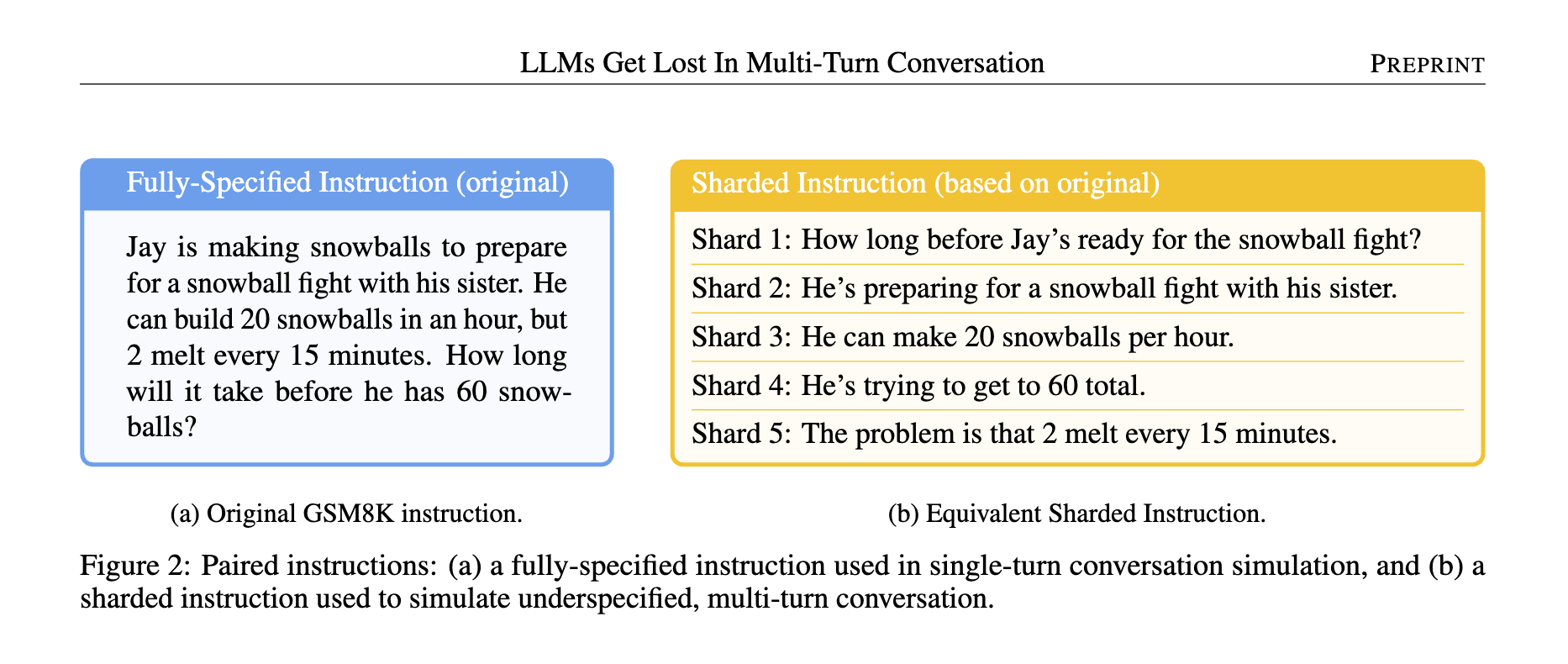
2.2 上下文工程技术(Techniques in CE)
前面我们提到了在实际应用中上下文出现不足、过长、矛盾和混淆等问题。本节我们将总览几类可用于解决这些问题的上下文工程技术。它们各自针对不同挑战,在系统架构中承担不同职责。更深入的技术细节和实现方式将在第二部分具体展开。 这里我会将上下文涉及的一些技术手段划分为这三个类别:- 上下文增强(Context Augmentation):主要目的是补充信息,比如提示词技术、RAG 和 MCP
- 上下文优化(Context Optimization):主要目的是清洗和优化上下文,会包括隔离、修剪和压缩等手段
- 上下文持久化(Context Persistence):主要目的是保留信息,涉及一些外部记忆模块的持久化服务
2.2.1 上下文增强(Context Augmentation)
提示词技术(Prompting)
提示词技术也就是 Prompting,一直以来就是为了增强模型输出的存在,虽然现在我们关注的目标是上下文,但是提示词技术仍然是上下文工程里很重要的一个东西,最基础的就是写好系统提示词。现在几乎所有的 AI 应用和产品都离不开提示词,甚至有些服务里会有很多的提示词,需要在不同的场景下加载不同的提示词到上下文中。 我们会着重关注在一些主流的提示词技术,来帮助我们写出更好、更适用的提示词。RAG(Retrieval-Augmented Generation)
RAG 是一种结合检索外部文档来辅助推理,提高结果准确性的技术:通过从外部知识库中检索相关信息,再将其与用户输入一同送入生成模型,从而提升响应的准确性与上下文的丰富性。 其优势在于:- 减少幻觉(Hallucination)
- 提升信息的时效性
- 专业或领域信息增强
- 索引:切分策略(语义/结构化切分)、元数据(时间、作者、标签)、多索引(向量 + 倒排)、段落-表格-图片多模态
- 查询加工:重写(Query Rewriting)、多路查询(Multi-Query)、分解(Decomposition)、意图判别(是否需要检索)
- 检排:向量召回 + 交叉编码器重排(Rerank);MMR/多样性;新鲜度与时效权重
- 变体:多跳/链式 RAG、Agentic RAG(规划 + 迭代检索)、GraphRAG(图结构汇总)、结构化检索(SQL/知识图谱)
工具集成与函数调用(MCP)
当模型自身通过训练得到的权重里包含的基础知识和上下文内容结合都无法回答用户问题的时候,模型可以基于预定的外部工具来获取外部数据或执行相应的任务。这一配套相当于解放了模型,使模型从一个孤岛系统成功接入了现实世界,可以从浏览器、本地计算机、外部接口等地方获取相应的数据来辅助决策,也可以直接执行某些动作,比如创建一个日程待办,发送一封邮件等等。 甚至现在具身智能领域为模型配上了类人的躯体,拥有视觉、触觉,有四肢可以与现实世界交互,得到信息,决策后续采取的行动。本质上模型就类似人类的大脑,人类也是解决外部的工具与这个世界交流,眼睛、鼻子、耳朵和手脚等都可以收集相应的信息,进而基于这些信息与我们自身已经学到的知识做出合适的决策和行动。 在大语言模型刚流行的头两年,不同模型都各自实现了工具调用(Tool Calling)或函数调用(Function Calling),在 2024 年 11 月 Anthropic 推出了 MCP(Model Context Protocol),旨在规范模型与外部环境的交互过程,推动上下文管理与工具调用机制的标准化。这也是我在这个小标题里的英文写的是 MCP,因为目前大部分模型厂商都宣布支持 MCP,以 MCP 为主的服务也不断涌现,因此我们会着重以 MCP 为出发点去了解这部分内容。 下面是一张我没找到出处但在网上广为流传的图,用于将 MCP 类比成 TypeC 的存在: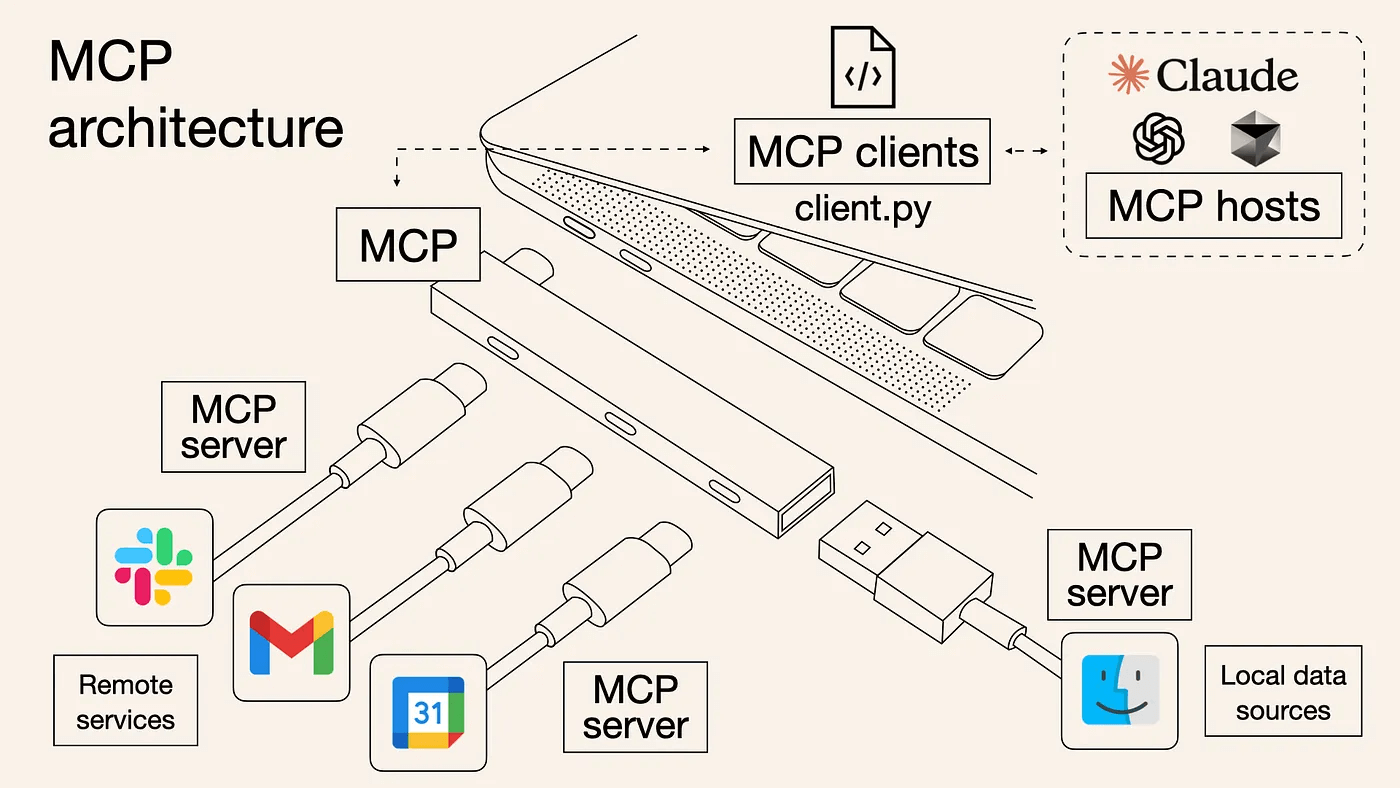
2.2.2 上下文优化(Context Optimization)
上下文隔离(Context Isolation)
这个技术在多智能体(Multi-Agent)上得到了极好的发挥。也就是将复杂任务通过拆分,细化成多个智能体(Agent),每个智能体单独执行专一的任务,每个智能体拥有独立的上下文窗口,可以使用合适的 MCP 服务,可以搭配不同的 RAG 等,正因为隔离,所以多个智能体之间无需关注非必要的上下文,进而减少了干扰。 多智能体是上下文隔离的一种应用,在不同的应用场景下,还有其他的一些手法:- 任务分片(Task Sharding):将任务分成多个子流程或阶段,每一阶段单独运行于自己的上下文中,避免累积无关信息
- 记忆系统分区(Memory Partitioning):通过将长期记忆和短期记忆隔离管理,只在需要时引用跨区域记忆,避免上下文污染
- 领域专属上下文(Domain-specific Context Pools):为不同的任务域(如法律、医疗、编程)配置专属上下文池,确保大语言模型使用最相关的信息
上下文压缩(Context Compression)
上下文压缩(Context Compression)或者也可以说是上下文摘要(Context Summarization),在某些地方也会以上下文修剪(Context Pruning) 出现,可以视为相同的东西,但是我觉得上下文压缩会比较贴切一点,且涵盖的范围更广一点。这一策略最早的出现是为了应对上下文窗口不足的问题,但是现在依然是一个非常重要的技术。常见的上下文压缩策略包括:- 提取式摘要(Extractive Summarization):直接选出原文中最相关的段落、句子
- 抽象式摘要(Abstractive Summarization):用自己的话总结信息,常结合 LLM 实现
- 结构化摘要(Structured Summarization):提取出知识点、任务、目标等结构化信息,如 To-do 列表、决策路径
- 自我总结(Self-summarization):模型每一轮对话之后,自动总结这轮信息并作为输入传递,形成压缩上下文链
- 摘要记忆(Summarized Memory):结合记忆机制,将历史摘要作为长期记忆引用
- 时间窗口裁剪(Time-based Pruning):仅保留最近或关键时段的上下文,剔除历史冗余信息,提升推理精度
可以看到,这里应用了提示词技术,来指示大模型通过什么样的方式来进行上下文压缩,这一段非常值得学习,说是压缩,其实结合了 9 个不同方向的摘要,这样确保重要信息都压缩保留,如果没有明确指示这 9 点的话,可能会导致压缩的时候其中一些重要的信息被过滤掉,导致后续执行的效果下降。
2.2.3 上下文持久化(Context Persistence)
上下文持久化(Context Persistence)指的是将模型历史的上下文内容,尤其是重要的用户信息、对话摘要、任务状态等进行长期存储,以便后续访问和复用。这类机制在类人交互系统、Agent 系统中非常关键,它帮助模型记住用户的偏好、上下文、历史任务等信息。 上下文持久化的典型方式包括: 存储介质:- 文件系统(如.json, .txt)
- 数据库存储(PostgreSQL, MongoDB 等)
- 向量数据库(用于检索式记忆)
- Key-Value 缓存(如 Redis)
- 会话记忆(Chat Memory):例如对话中用户提到”我下周要去东京”,可以在后续对话中继续引用;
- Agent 任务状态保存:例如 Agent 正在处理一个流程任务,下次接入可从断点恢复;
- 用户偏好记录:如用户喜欢 markdown 格式、喜欢精炼回答等。
- 自动摘要持久化(如每天一次自动保存摘要)
- 用户关键输入保存(如计划、目标等)
- 分阶段持久化(如每完成一个任务后存储)